

Seu negócio pode parar por horas — ou dias — se um desastre atingir seus sistemas. Mas a verdadeira dor não é o desastre em si; é descobrir que seu backup não funcionou ou que o tempo de restauração vai custar milhões. A recuperação de desastres não é um luxo: é o que separa quem sobrevive de quem fecha as portas.
Muita gente acha que ter um backup resolve tudo. Só que backup não é recuperação. Sem um plano estruturado, com métricas claras como RPO e RTO, você está apostando que o pior não vai acontecer. E quando acontece, a conta vem salgada.
O que é recuperação de desastres de TI e por que seu plano precisa de RPO e RTO
Recuperação de desastres (DR) é o conjunto de políticas, ferramentas e procedimentos para restaurar sua infraestrutura de TI após uma interrupção — seja um ataque cibernético, uma falha de hardware ou até um desastre natural. O coração do planejamento está em dois indicadores: o RPO (objetivo de ponto de recuperação), que define quantos dados você pode perder, e o RTO (objetivo de tempo de recuperação), que estipula o tempo máximo para os sistemas voltarem ao ar.
Na prática, um plano eficaz começa com uma avaliação de riscos — identificar ameaças como ransomware ou falhas na nuvem — e uma análise de impacto nos negócios (BIA) para priorizar os sistemas críticos. Empresas que usam DRaaS (Disaster Recovery as a Service) em plataformas como AWS, Azure ou Google Cloud conseguem replicar dados em tempo real e reduzir o RTO para minutos, com custo muito menor que manter um site quente próprio.
Recuperação de Desastres em 2026: O Escudo Essencial para a Continuidade do Seu Negócio

Em 2026, a Recuperação de Desastres (DR) transcendeu a categoria de boa prática para se tornar um pilar inegociável da resiliência empresarial. Trata-se de um conjunto orquestrado de políticas, ferramentas e procedimentos meticulosamente planejados para garantir que sua infraestrutura de TI possa ser restaurada rapidamente após qualquer tipo de interrupção. Ignorar a DR é, em essência, convidar o caos a tomar conta dos seus dados e operações, comprometendo a confiança dos seus clientes e a própria sobrevivência da sua organização em cenários de desastres de TI.
O planejamento eficaz da Recuperação de Desastres de TI se apoia em métricas cruciais: o Objetivo de Ponto de Recuperação (RPO), que define a janela máxima de perda de dados aceitável, e o Objetivo de Tempo de Recuperação (RTO), estabelecendo o limite de tempo para restabelecer sistemas. Compreender e definir esses parâmetros é o primeiro passo para construir um sistema robusto de proteção de dados e garantir a continuidade de negócios.
| Indicador | Definição | Relevância |
|---|---|---|
| RPO (Objetivo de Ponto de Recuperação) | Perda máxima de dados tolerável em tempo. | Define a frequência dos backups e a granularidade da restauração. |
| RTO (Objetivo de Tempo de Recuperação) | Tempo máximo para restabelecer sistemas críticos. | Determina a urgência e os recursos necessários para a recuperação. |
| BIA (Análise de Impacto nos Negócios) | Identifica e prioriza sistemas críticos. | Base para definir RPO e RTO adequados. |
| Avaliação de Riscos | Identifica ameaças potenciais (ciberataques, falhas). | Direciona as estratégias de mitigação e prevenção. |
O que é Recuperação de Desastres
Recuperação de Desastres, no contexto de 2026, é a disciplina que permite a uma organização se recuperar de eventos que causam interrupções significativas em suas operações de TI. Isso vai muito além de simples backups; envolve um plano estratégico completo para restaurar dados, aplicações e infraestrutura de forma rápida e eficiente. A meta é minimizar o tempo de inatividade e a perda de dados, assegurando que os negócios possam continuar operando mesmo diante de adversidades, sejam elas naturais ou provocadas pelo homem.
Leia também: 42 ideias de lobo dc para turbinar seu data center
Sem uma estratégia de DR bem definida, sua empresa fica vulnerável a perdas financeiras substanciais, danos à reputação e, em casos extremos, ao encerramento das atividades. A proteção de dados é a espinha dorsal dessa disciplina, garantindo que informações valiosas não se percam irremediavelmente em meio a um incidente.
Plano de Recuperação de Desastres de TI
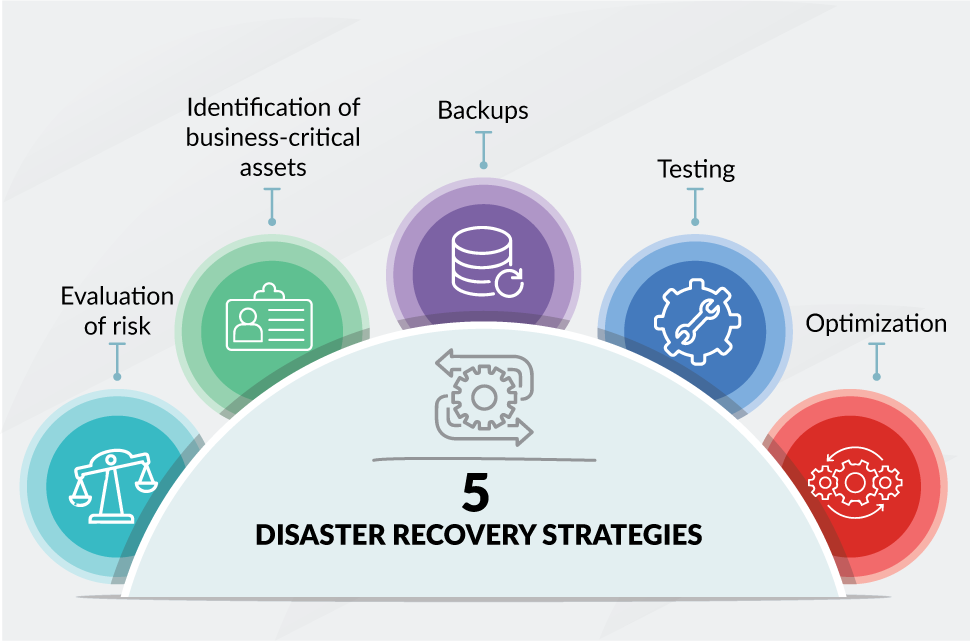
Um Plano de Recuperação de Desastres de TI (DRP) é o documento mestre que detalha os procedimentos a serem seguidos para restaurar os sistemas de tecnologia da informação após uma falha. Ele é construído com base em uma análise aprofundada dos riscos e do impacto nos negócios, garantindo que os recursos sejam alocados de forma inteligente. Este plano deve ser claro, acessível e testado regularmente para garantir sua eficácia em momentos de crise.
A elaboração de um DRP eficaz é um processo contínuo, que exige revisões periódicas para se adaptar às mudanças tecnológicas e aos novos cenários de ameaças.
DRP: Como Funciona na Prática
Na prática, a implementação de um DRP envolve várias etapas cruciais. Começa com a Avaliação de Riscos, onde se identificam as ameaças mais prováveis, como ataques cibernéticos, falhas de hardware, desastres naturais ou erros humanos. Em seguida, a Análise de Impacto nos Negócios (BIA) é realizada para determinar quais sistemas e processos são mais críticos para a operação e qual o impacto financeiro e operacional de sua indisponibilidade.
Com base nesses dados, são definidas as Estratégias de Resposta, que podem incluir a replicação de dados em tempo real, a manutenção de sites secundários (hot sites ou cold sites) ou a contratação de serviços de DRaaS. A etapa final e vital é a Implementação e Testes rigorosos do plano, simulando cenários de desastre para validar se os procedimentos funcionam conforme o esperado e se os objetivos de RPO e RTO são atingidos. A restauração de sistemas é o objetivo final de todo esse processo.
Leia também: Falha de San Andreas: o que você precisa saber sobre o ‘Big One’
Recuperação de Desastres na AWS

A Amazon Web Services (AWS) oferece um ecossistema robusto para a implementação de soluções de recuperação de desastres, permitindo que empresas criem estratégias flexíveis e escaláveis. Utilizando serviços como o AWS Elastic Disaster Recovery (DRS), é possível replicar servidores on-premises ou em outras nuvens para a AWS e realizar failover de forma rápida em caso de desastre. A infraestrutura global da AWS garante que você possa ter um site de recuperação em uma região geograficamente distante da sua operação principal, mitigando riscos regionais.
A AWS também possibilita a criação de arquiteturas de alta disponibilidade e resiliência que minimizam a necessidade de um plano de recuperação tradicional. Estratégias como o uso de múltiplos Availability Zones e Regiões, backups automatizados com o AWS Backup e a replicação de bancos de dados com o Amazon RDS são fundamentais. A recuperação de desastres AWS se beneficia enormemente da elasticidade da nuvem, permitindo ajustar os recursos conforme a necessidade e otimizar custos.
Recuperação de Desastres no Azure
O Microsoft Azure, assim como a AWS, dispõe de um conjunto abrangente de serviços para recuperação de desastres. O Azure Site Recovery é a ferramenta central, permitindo a replicação de máquinas virtuais e servidores físicos para a nuvem Azure, com orquestração de failover e failback. Isso garante que, mesmo em caso de falha em seu data center principal, suas cargas de trabalho críticas possam ser rapidamente ativadas no Azure.
Além do Azure Site Recovery, a plataforma oferece soluções como o Azure Backup para cópias de segurança e o Azure SQL Database geo-replication para proteção de bancos de dados. A integração com outras ferramentas de gerenciamento e monitoramento do Azure permite uma visão unificada do ambiente e uma resposta mais ágil a incidentes. A recuperação de desastres Azure se destaca pela sua profunda integração com o ecossistema Microsoft, facilitando a proteção de ambientes híbridos.
Recuperação de Desastres no Google Cloud
O Google Cloud Platform (GCP) também apresenta soluções robustas para recuperação de desastres, focando em resiliência e escalabilidade. Através de serviços como o Google Cloud Disaster Recovery solutions, é possível projetar arquiteturas que garantam a continuidade dos negócios. A estratégia pode envolver a replicação de dados para instâncias do Compute Engine em diferentes regiões, o uso de bancos de dados gerenciados com replicação automática, como o Cloud SQL, e backups automatizados.
O GCP incentiva o uso de abordagens como o
Leia também: Dump o que e? Do Instagram ao backup, entenda tudo
Estratégias de Recuperação que Funcionam na Prática
- Defina RPO e RTO realistas antes de escolher qualquer ferramenta. Sem esses números, seu plano de DR é apenas um desejo.
- Teste seu plano de recuperação a cada trimestre, simulando falhas reais. Um DRP não testado é tão confiável quanto uma aposta.
- Opte por DRaaS se sua equipe de TI é enxuta. Provedores como AWS e Azure gerenciam a complexidade da replicação e failover.
- Documente cada etapa do procedimento de recuperação em um runbook detalhado. Em meio ao caos, um guia claro reduz o tempo de resposta.
- Automatize a orquestração da recuperação sempre que possível. Scripts e ferramentas de automação eliminam erros manuais e aceleram a restauração.
Perguntas Frequentes sobre Recuperação de Desastres
Qual a diferença entre backup e recuperação de desastres?
Backup é a cópia dos dados; DR é o processo completo de restaurar sistemas e infraestrutura. Um backup sem plano de DR pode levar dias para ser útil.
Quanto custa implementar um plano de DR?
O custo varia conforme RTO e RPO desejados, mas soluções em nuvem reduzem investimento inicial. DRaaS pode custar de R$ 500 a R$ 10.000 mensais para PMEs.
Com que frequência devo testar meu plano de DR?
Testes trimestrais são o padrão recomendado para ambientes críticos. Testes anuais são insuficientes, pois mudanças na infraestrutura tornam o plano obsoleto.
Empresas que investem em DR bem planejado reduzem o downtime em até 80% e evitam perdas financeiras catastróficas. A escolha de uma estratégia alinhada ao seu orçamento e criticidade é o que separa a resiliência do improviso.
Comece mapeando seus sistemas críticos e calculando o custo de cada hora de inatividade. Em seguida, avalie provedores de DRaaS que ofereçam testes sem custo adicional.
O futuro da recuperação de desastres é preditivo, com IA antecipando falhas antes que ocorram. Sua empresa estará preparada para o próximo grande evento disruptivo.


