

Você já se viu afogado em dados brutos de diversas fontes, sem saber por onde começar a extrair valor? Um data lake resolve exatamente isso: um repositório centralizado que guarda tudo no formato original, sem exigir transformações prévias. É a base para quem quer escalar análises e Machine Learning sem engessar o processo.
Diferente de um data warehouse, que exige esquemas rígidos na escrita, o data lake adota o ‘esquema na leitura’ — você decide como estruturar os dados só quando for usá-los. Isso dá liberdade total para explorar, testar hipóteses e inovar com agilidade. Mas atenção: sem governança, seu lake vira um pântano (data swamp).
Data lake vs data warehouse: entenda as diferenças práticas
A principal distinção está no momento da definição do esquema. No data warehouse, os dados são limpos e modelados antes do armazenamento (esquema na escrita), ideal para relatórios de BI com performance previsível. Já no data lake, os dados ficam crus, em seu formato nativo — sejam logs JSON, imagens ou tabelas relacionais —, permitindo que cientistas de dados os explorem sem restrições.
Outro ponto é o custo: data lakes em nuvem (como Amazon S3, Azure Data Lake Storage ou Google Cloud Storage) oferecem armazenamento barato e escalável, enquanto warehouses costumam ser mais caros por GB. Mas não se engane: a flexibilidade do lake exige um catálogo de metadados robusto e governança ativa para evitar o caos. Ferramentas como Apache Atlas, AWS Glue e Azure Purview ajudam a manter a ordem.
Data Lake: O Reservatório Inteligente de Dados para o Futuro
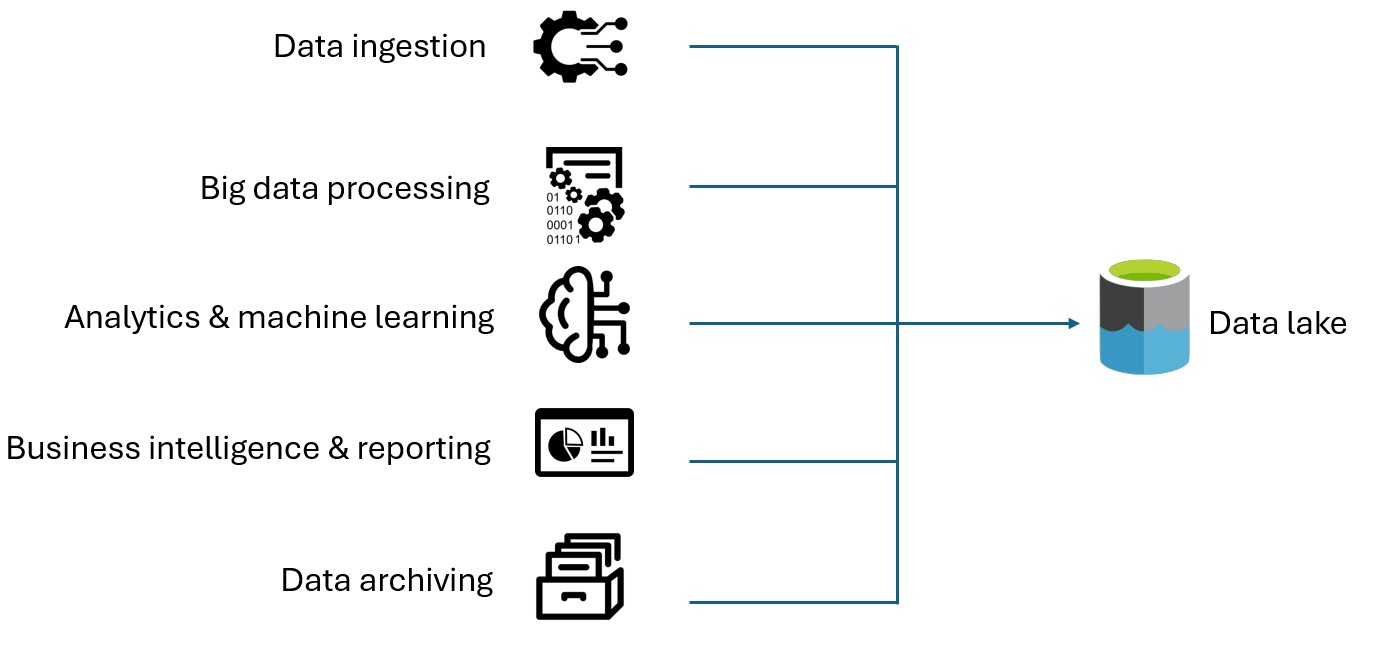
Muita gente pensa que um data lake é só um monte de dados jogado sem organização, um verdadeiro caos digital. Mas a verdade é que ele é, na verdade, um repositório centralizado e escalável, projetado para guardar volumes gigantescos de dados brutos no formato em que chegam. Pense nele como um lago de verdade: a água (seus dados) entra de várias fontes (rios, chuva) e fica ali, pronta para ser usada quando precisar, sem precisar ser tratada antes.
| Característica | Descrição |
| Armazenamento | Centralizado e escalável |
| Tipos de Dados | Estruturados, semiestruturados e não estruturados (áudio, vídeo, texto, etc.) |
| Formato dos Dados | Brutos, em seus formatos nativos |
| Esquema | Esquema na leitura (flexível) |
| Usuários Principais | Cientistas e engenheiros de dados |
| Casos de Uso | Exploração de dados, Machine Learning, IA |
| Custo | Baixo custo de armazenamento em nuvem |
| Benefícios Chave | Escalabilidade, flexibilidade, centralização, prontidão para IA |
| Diferença Principal (vs. DW) | Dados brutos vs. dados processados; esquema na leitura vs. esquema na escrita |
Data Lake descomplicado
O conceito é simples: coletar tudo que sua empresa gera, sem se preocupar em classificar ou transformar na hora. Isso significa que imagens, áudios, planilhas, logs de sistema, tudo pode ir para o mesmo lugar. Essa liberdade é o que permite explorar novas possibilidades analíticas que antes eram impossíveis.
Essa abordagem de esquema na leitura, diferente do tradicional esquema na escrita, dá uma agilidade incrível para o trabalho de cientistas de dados. Eles podem moldar os dados da maneira que precisam para cada análise específica, sem depender de processos demorados de ETL (Extração, Transformação, Carga).
A flexibilidade do data lake é seu maior trunfo. Permite que as equipes de dados sejam mais ágeis na exploração e descoberta de insights.
Data Lake vs Data Warehouse
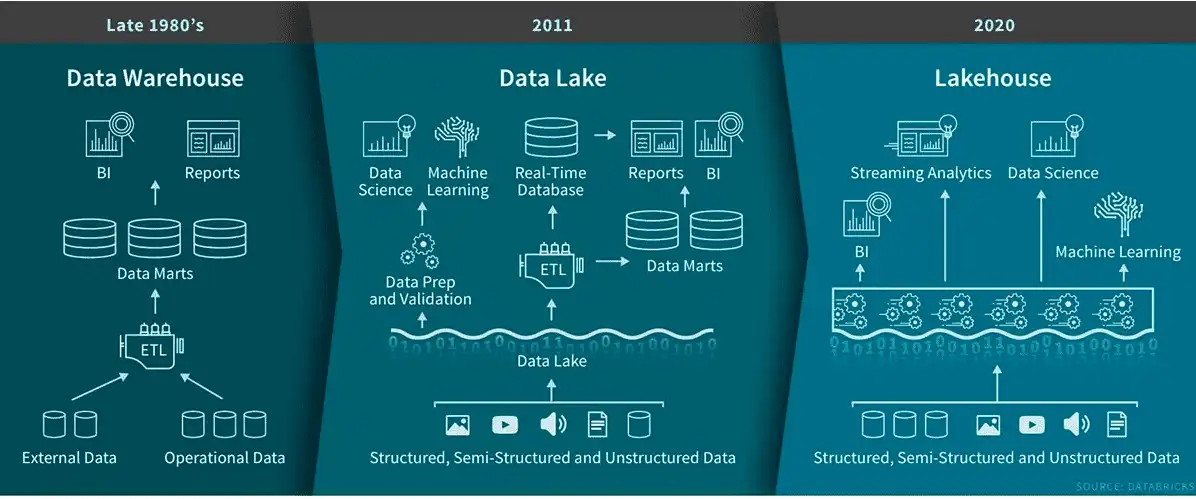
Vamos combinar: a diferença é gritante. Enquanto o Data Warehouse é focado em dados estruturados e processados, como relatórios de vendas já organizados, o data lake abraça todo tipo de dado, bruto e sem tratamento prévio. O Data Warehouse é como uma biblioteca organizada, com livros classificados por tema, ideal para consultas rápidas e análises de Business Intelligence (BI). Já o data lake é um oceano de informações, onde você pode mergulhar para encontrar tesouros escondidos.
Imagine uma loja de varejo. O Data Warehouse teria os dados de vendas já consolidados por produto e loja. O data lake conteria esses dados, mas também imagens dos produtos, reviews de clientes em texto livre, vídeos de demonstração e até dados de sensores de loja, tudo pronto para análises preditivas ou de sentimento.
Essa distinção é crucial para entender onde cada ferramenta brilha. Se você precisa de relatórios padronizados e análises de desempenho claras, o Data Warehouse é o caminho. Para inovações e explorações profundas, o data lake se mostra indispensável.
Benefícios do Data Lake
O principal benefício é a escalabilidade. Com as soluções em nuvem, você pode armazenar petabytes de dados a um custo relativamente baixo. Isso democratiza o acesso a grandes volumes de informação para sua empresa.
Além disso, a centralização dos ativos de dados acaba com os silos de informação. Todas as áreas da empresa podem acessar a mesma fonte de verdade, promovendo colaboração e reduzindo redundâncias. Isso também é um passo fundamental para a prontidão de sua organização em adotar Inteligência Artificial (IA).
A capacidade de armazenar e processar dados de qualquer formato é o que impulsiona a inovação com IA e Machine Learning.
Arquitetura do Data Lake
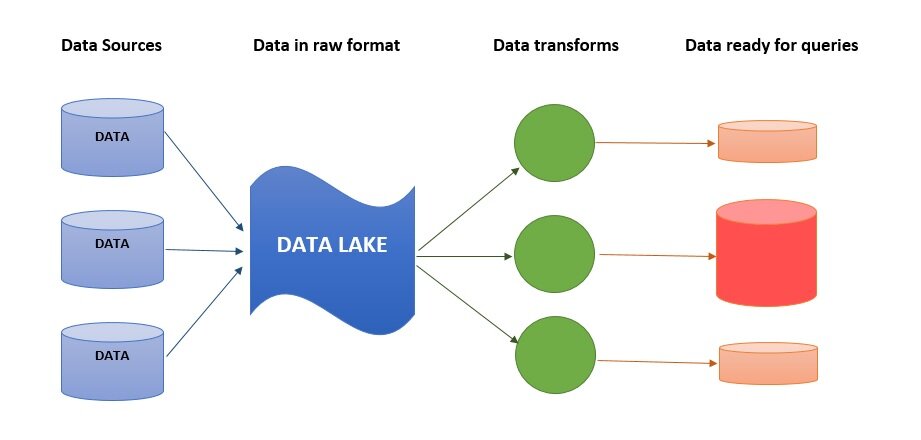
A arquitetura de um data lake geralmente envolve camadas. A camada de ingestão traz os dados de diversas fontes. Em seguida, vêm as camadas de armazenamento, onde os dados brutos e processados residem. Por fim, a camada de consumo oferece acesso aos dados para diferentes usuários e aplicações, como ferramentas de análise e modelos de ML.
A organização interna é vital. Mesmo sendo um repositório de dados brutos, é preciso ter uma estrutura que permita a descoberta e o acesso. Ferramentas de catalogação e metadados são essenciais aqui, como veremos mais adiante.
A forma como os dados são organizados e catalogados impacta diretamente a eficiência das análises. Um data lake bem estruturado acelera o tempo de obtenção de insights.
Data Lake na nuvem
A nuvem transformou os data lakes. Serviços como Amazon S3, Azure Data Lake Storage e Google Cloud Storage oferecem armazenamento escalável, durável e de baixo custo. Essa infraestrutura elástica permite que sua empresa cresça sem se preocupar com limitações de hardware.
A migração para a nuvem não é apenas sobre economia, mas também sobre agilidade. Você pode provisionar recursos em minutos, experimentar novas tecnologias e escalar conforme a demanda, algo impensável com infraestrutura on-premise. Confira mais detalhes em AWS sobre Data Lake.
A nuvem é o ambiente ideal para a escalabilidade e o custo-benefício dos data lakes modernos.
Governança no Data Lake
Aqui é onde muitos tropeçam. Sem uma governança de dados robusta, o data lake pode virar um caos. Ferramentas de catalogação, linhagem de dados e controle de acesso são fundamentais para garantir que os dados sejam confiáveis, seguros e utilizáveis.
É preciso definir quem pode acessar o quê, como os dados são classificados e quem é o responsável por cada conjunto de dados. Ignorar isso é o caminho mais rápido para a perda de confiança nos dados.
A falta de governança adequada pode comprometer toda a estratégia de dados de uma empresa.
Data Swamp: perigo real
O temido data swamp, ou pântano de dados, é o resultado direto da falta de governança. Dados sem contexto, sem qualidade e sem controle se tornam inúteis, ou pior, levam a decisões erradas. É como um lago cheio de lodo, onde nada mais pode prosperar.
Para evitar isso, invista em ferramentas de catalogação de metadados e estabeleça políticas claras de gestão de dados desde o início. A curadoria contínua é a chave para manter seu lago limpo e produtivo. Veja como a IBM aborda o tema.
Um data swamp não é apenas um problema técnico, é um obstáculo estratégico que impede a inovação.
Data Lakehouse: evolução natural
O Data Lakehouse surge como a união do melhor dos dois mundos: a flexibilidade e o baixo custo do data lake com a estrutura e a gestão de dados do data warehouse. Ele permite que você execute cargas de trabalho de BI e IA diretamente sobre os dados brutos do seu data lake, com performance e confiabilidade.
Essa arquitetura moderna busca simplificar a infraestrutura de dados, eliminando a necessidade de manter sistemas separados para diferentes tipos de análise. É a evolução natural para empresas que buscam maximizar o valor de seus dados.
Soluções como Delta Lake, Apache Iceberg e Apache Hudi são pilares dessa nova abordagem, trazendo transações ACID e esquemas mais robustos para o data lake. Leia mais sobre Data Hub, Data Lake e Data Warehouse para entender as nuances.
O Futuro dos Dados em 2026: O Data Lake como Pilar Estratégico
Em 2026, o data lake não será mais uma opção, mas sim um componente essencial da infraestrutura de dados de qualquer empresa que queira ser competitiva. A capacidade de processar e analisar volumes massivos de dados em tempo real, de qualquer formato, é o que vai diferenciar os líderes de mercado.
A tendência é clara: a adoção de arquiteturas como o Data Lakehouse vai se intensificar, unificando a gestão e a análise de dados. As empresas que investirem em governança e em ferramentas de catalogação agora estarão um passo à frente.
O verdadeiro poder do data lake reside na sua capacidade de desmistificar o acesso à informação e impulsionar a inovação. É o alicerce para a inteligência artificial e a tomada de decisão baseada em dados. Se você ainda não tem um, 2026 é o ano para começar a planejar o seu. Confira mais em Alura sobre Data Lake.
Seu Plano de Ação para um Data Lake Eficiente
Siga três passos essenciais para transformar teoria em prática. Comece hoje mesmo a estruturar seu data lake com governança e escalabilidade.
1. Defina Objetivos e Governança
- Estabeleça políticas claras de acesso e qualidade de dados.
- Documente metadados desde o primeiro arquivo ingerido.
2. Escolha a Infraestrutura Ideal
- Prefira soluções em nuvem como AWS S3, Azure Data Lake Storage ou Google Cloud Storage.
- Considere custos de armazenamento e computação separados para escalabilidade.
3. Implemente Catalogação e Metadados
- Use ferramentas como Apache Atlas, AWS Glue ou Azure Purview.
- Automatize a descoberta de esquemas e a linhagem dos dados.
Perguntas Frequentes
Qual a diferença entre data lake e data warehouse?
Data lakes armazenam dados brutos sem esquema pré-definido, enquanto data warehouses exigem transformação e esquema na escrita. Data lakes são ideais para exploração e machine learning; data warehouses para BI e relatórios estruturados.
Como evitar que meu data lake vire um data swamp?
Implemente governança robusta com catalogação de metadados, políticas de qualidade e linhagem de dados. Automatize processos de ingestão e aplique controles de acesso granulares.
Data lake é adequado para BI?
Sim, com ferramentas como Presto, Athena ou Spark SQL é possível consultar dados diretamente. No entanto, para performance em dashboards, considere camadas de otimização como tabelas particionadas e formatos columnar (Parquet).
Data lakes são a base para inovação em dados, unindo flexibilidade e escalabilidade. Com governança correta, você evita o caos e extrai valor real.
Comece mapeando suas fontes de dados e definindo um piloto. Em paralelo, invista em cultura de metadados e treinamento da equipe.
Visualize um repositório onde todos os dados da empresa conversam entre si. É o futuro da inteligência corporativa, acessível e pronto para descobertas.