

O log de servidor é aquele erro que todo mundo ignora, mas que pode custar caro à sua operação. Vou te mostrar por que ele é essencial e como usá-lo a seu favor.
O que é um log de servidor e por que ele é o seu melhor aliado na TI
Imagine o log como o diário de bordo do seu servidor. Ele registra tudo: cada acesso, cada erro, cada tentativa de ataque. Fica tranquilo, não é só uma lista chata de eventos.
Para você, administrador ou desenvolvedor, ele é a ferramenta mais poderosa para diagnóstico. Quando algo dá errado, o log te conta a história completa, com timestamps e códigos de status que revelam a raiz do problema. Vamos combinar, sem ele, você está trabalhando no escuro.
Em Destaque 2026: Um log de servidor é um arquivo de texto gerado automaticamente que registra todas as atividades e eventos que ocorrem em um servidor, funcionando como um diário de bordo para monitoramento e diagnóstico.
O Que é um Log de Servidor e Por Que Ele é o Herói Invisível da Sua Infraestrutura
Pois é, meu amigo, quando a gente fala de servidores, a maioria pensa em máquinas potentes, redes velozes e softwares rodando sem parar. Mas tem um detalhe que muita gente ignora, e que pode custar caro: os logs de servidor. Esses registros são, na verdade, o diário de bordo da sua infraestrutura. Eles anotam tudo o que acontece, desde o acesso mais simples até a tentativa mais ardilosa de invasão. Sem eles, você fica cego, sem saber o que está rolando de verdade.
Para administradores de sistemas e desenvolvedores, os logs são como um mapa do tesouro para encontrar problemas. Sabe aquele erro que aparece do nada e ninguém sabe explicar? O log geralmente tem a resposta. Eles registram atividades, eventos, falhas de software, acessos e até tentativas de ataque. Ter essa informação detalhada é crucial para manter tudo funcionando redondinho e seguro. É a base para qualquer diagnóstico eficiente e para garantir a estabilidade do seu sistema.
Vamos combinar, confiar apenas na intuição para gerenciar um servidor é furada. Os logs de servidor oferecem dados concretos, com timestamps precisos, URLs acessadas e códigos de status HTTP. Isso permite um monitoramento detalhado e proativo. Seja para identificar um comportamento inesperado do sistema ou para reforçar a segurança, os logs são seus melhores aliados. Eles são a prova do que aconteceu e a chave para entender o futuro do seu ambiente de TI.
| Característica | Descrição |
|---|---|
| Registro de Atividades | Anota todos os eventos e ações ocorridas no servidor. |
| Diagnóstico de Falhas | Essencial para identificar e solucionar erros de software e hardware. |
| Monitoramento de Segurança | Registra acessos, tentativas de invasão e atividades suspeitas. |
| Informações Detalhadas | Contém timestamps, URLs, códigos de status HTTP e outros dados relevantes. |
| Tipos Comuns | Logs de acesso, logs de erro, logs do sistema operacional. |
| Visualização (Windows) | Acessados via Event Viewer. |
| Visualização (Linux) | Geralmente encontrados em /var/log/. |
| Centralização | Ferramentas como Graylog e Nagios unificam logs de múltiplos dispositivos. |
O Que São Registros de Servidor e Como Funcionam
Registros de servidor, ou logs, são arquivos que documentam sistematicamente as atividades e eventos que ocorrem em um servidor. Pense neles como um diário detalhado, onde cada entrada é um evento específico, timestampado e com informações contextuais. Eles são gerados por diversos componentes do sistema, desde o sistema operacional até aplicações específicas. O funcionamento é simples: quando um evento acontece – seja um usuário fazendo login, um erro de aplicação, ou uma requisição web – o servidor registra essa ocorrência em um arquivo de log. Essa gravação automática é o que nos permite, posteriormente, analisar o que aconteceu, quando aconteceu e, muitas vezes, por que aconteceu.
A importância desses registros transcende a mera curiosidade. Para administradores de sistemas, eles são ferramentas indispensáveis para a manutenção, o monitoramento e a solução de problemas. Desenvolvedores os utilizam para depurar códigos e entender o comportamento de suas aplicações em produção. A capacidade de rastrear eventos com precisão é o que diferencia um ambiente estável de um caótico. Sem logs, diagnosticar falhas se torna um exercício de adivinhação, aumentando o tempo de inatividade e o impacto nos negócios.
Esses arquivos são a espinha dorsal da observabilidade de um servidor. Eles contêm informações cruciais como timestamps exatos, as URLs que foram acessadas, os códigos de status HTTP retornados (como 200 OK, 404 Not Found ou 500 Internal Server Error), endereços IP de origem, e mensagens de erro detalhadas. Essa riqueza de dados permite não apenas identificar problemas pontuais, mas também detectar padrões, anomalias e tendências ao longo do tempo. É a base para uma gestão proativa e eficiente da infraestrutura de TI.
Principais Tipos de Arquivos de Log em Servidores
Dentro do universo dos logs de servidor, existem diferentes tipos, cada um focado em um aspecto específico da operação. Vamos detalhar os mais comuns para você entender a granularidade: os logs de acesso, por exemplo, registram todas as requisições feitas a um servidor web. Eles mostram quem acessou o quê, quando e de onde, sendo fundamentais para análise de tráfego e segurança. Em seguida, temos os logs de erro. Estes são vitais para desenvolvedores e administradores, pois detalham quaisquer falhas, exceções ou mensagens de aviso que ocorrem durante a execução de softwares ou do próprio sistema operacional. Eles são o primeiro lugar para procurar quando algo não está funcionando como deveria.
Além desses, os logs do sistema operacional fornecem uma visão geral das atividades do próprio SO, como eventos de inicialização, desligamento, falhas de serviços, e atividades de usuários no nível do sistema. No ambiente Windows Server, por exemplo, a visualização desses logs é feita de maneira centralizada através do Event Viewer, que organiza os eventos em categorias como Application, Security e System. Já em sistemas Linux, a convenção é que a maioria dos logs esteja localizada no diretório /var/log/, com arquivos específicos para diferentes serviços e componentes do sistema, como syslog, auth.log, e logs de servidores web como Apache e Nginx.
Compreender a função de cada tipo de log é o primeiro passo para uma gestão eficaz. Saber onde encontrar e como interpretar essas informações permite que você não apenas reaja a problemas, mas também antecipe e previna muitas das dores de cabeça comuns na administração de servidores. É um conhecimento que faz toda a diferença no dia a dia.
Como Fazer o Monitoramento de Servidor Através de Logs
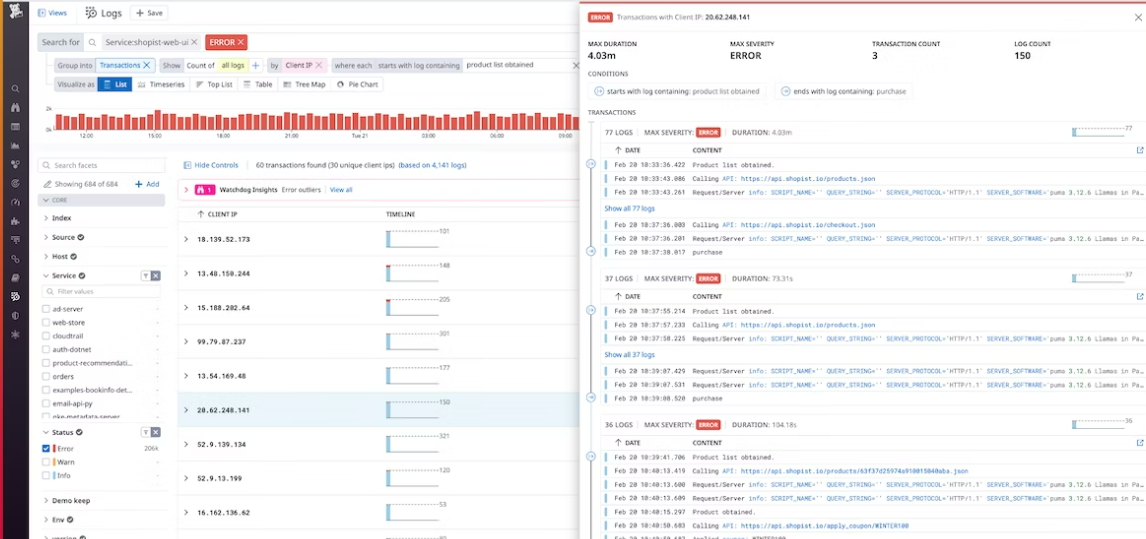
O monitoramento de servidor usando logs é uma prática essencial para garantir a saúde e a segurança da sua infraestrutura. Em vez de esperar um problema se manifestar e causar interrupções, o monitoramento proativo permite identificar sinais de alerta precocemente. Isso é feito analisando continuamente os dados registrados nos arquivos de log. Por exemplo, um aumento súbito no número de erros 5xx em logs de acesso pode indicar um problema com a aplicação ou o servidor web. Da mesma forma, padrões incomuns em logs de autenticação podem sinalizar tentativas de força bruta ou acesso não autorizado.
Para tornar esse processo mais eficiente, especialmente em ambientes com múltiplos servidores e serviços, a centralização de logs é fundamental. Ferramentas como Graylog e Nagios (ou soluções mais modernas como ELK Stack e Splunk) são projetadas para coletar logs de diversos dispositivos e aplicações em um único local. Isso não só facilita a visualização e a análise, mas também permite a configuração de alertas automáticos. Você pode definir regras para ser notificado imediatamente quando certos eventos ocorrerem, como falhas críticas ou picos de atividade suspeita. Essa capacidade de resposta rápida é o que salva o dia em muitas situações.
A chave para um monitoramento eficaz é a correlação de eventos entre diferentes fontes de log. Um problema em uma aplicação pode ser apenas um sintoma de uma falha subjacente no sistema operacional ou na rede. Ao centralizar e analisar logs de forma cruzada, você consegue ter uma visão holística do que está acontecendo. Isso permite não apenas diagnosticar a causa raiz mais rapidamente, mas também entender o impacto total de um incidente. É como montar um quebra-cabeça complexo, onde cada log é uma peça que ajuda a revelar a imagem completa.
Técnicas de Análise de Logs para Otimização de Sistemas
A análise de logs vai muito além de simplesmente procurar por erros. Quando feita corretamente, ela se torna uma poderosa ferramenta para otimizar o desempenho e a eficiência dos seus sistemas. Uma das técnicas mais eficazes é a análise de tendências. Ao examinar logs ao longo do tempo, você pode identificar padrões de uso, gargalos de desempenho e áreas onde os recursos estão sendo subutilizados ou sobrecarregados. Por exemplo, analisar logs de acesso a um site pode revelar quais páginas são mais populares, quais horários têm maior tráfego, e quais requisições estão demorando mais para serem processadas. Essas informações são ouro para otimizar o carregamento de páginas, ajustar a capacidade do servidor e melhorar a experiência do usuário.
Outra técnica valiosa é a análise de correlação. Como mencionei antes, sistemas complexos geram logs em diversas fontes. A correlação envolve cruzar informações de diferentes logs para entender a relação entre eventos. Por exemplo, um pico de latência em um serviço pode estar diretamente relacionado a um aumento no consumo de CPU registrado nos logs do sistema operacional, ou a um problema de rede evidenciado em logs de firewall. Ferramentas de análise de logs avançadas podem automatizar esse processo, identificando conexões ocultas e fornecendo insights que seriam quase impossíveis de obter manualmente.
Não se esqueça da análise de anomalias. Sistemas que operam normalmente tendem a seguir um padrão. Qualquer desvio significativo desse padrão, registrado nos logs, pode indicar um problema ou uma oportunidade de melhoria. Isso pode variar desde um aumento inesperado no número de falhas de autenticação até um padrão de acesso incomum a arquivos sensíveis. Identificar e investigar essas anomalias proativamente pode prevenir incidentes de segurança e garantir que o sistema esteja sempre operando em seu potencial máximo. É um trabalho contínuo de refinamento.
Diagnóstico de Sistema: Identificando Problemas Através de Logs
Quando um servidor começa a apresentar comportamento estranho – lentidão, travamentos, ou falhas em serviços – os logs de servidor são o primeiro lugar onde um especialista vai procurar. O diagnóstico de sistema baseado em logs é um processo metódico de investigação. Ele começa com a identificação dos sintomas observados e, em seguida, a busca nos registros por eventos que coincidam temporalmente com o início dos problemas. Por exemplo, se um site começou a ficar lento às 14h, o administrador revisará os logs de acesso e de erro do servidor web a partir desse horário.
A chave aqui é saber o que procurar. Um log de erro pode conter uma mensagem explícita indicando a causa raiz, como uma falha de conexão com o banco de dados, um arquivo corrompido, ou um limite de memória excedido. Logs de sistema operacional podem revelar problemas com drivers, falhas de hardware ou serviços que pararam de responder. A capacidade de interpretar os códigos de erro e as mensagens técnicas é fundamental. Muitas vezes, uma busca rápida na internet pelo código de erro específico pode levar à solução. É um trabalho de detetive digital.
É importante também correlacionar informações. Um erro em um log de aplicação pode ser apenas um reflexo de um problema mais profundo no sistema. Por isso, é comum analisar em conjunto os logs de aplicação, logs do sistema operacional e, se aplicável, logs de rede. Essa visão integrada permite descartar causas menos prováveis e focar na origem real do problema. Lembre-se, os logs não mentem; eles apenas registram os fatos. Saber ler esses fatos é o que permite um diagnóstico rápido e preciso, minimizando o tempo de inatividade e o impacto para os usuários.
Segurança de Servidor: Monitorando Ameaças com Logs de Acesso
No quesito segurança, os logs de servidor são absolutamente indispensáveis. Eles funcionam como as câmeras de segurança da sua infraestrutura, registrando quem entra, quem sai e o que está sendo feito. Os logs de acesso, em particular, são cruciais para monitorar tentativas de acesso não autorizado, ataques de força bruta, e atividades suspeitas. Ao analisar esses registros, você pode identificar padrões como múltiplas tentativas falhas de login de um mesmo IP, acessos a áreas restritas do sistema, ou picos incomuns de tráfego vindos de determinadas origens.
A análise de logs de segurança permite não apenas detectar uma invasão em andamento ou que já ocorreu, mas também entender a metodologia utilizada pelo atacante. Isso é vital para reforçar as defesas e prevenir futuros ataques. Por exemplo, se logs revelam que um atacante tentou explorar uma vulnerabilidade específica, você pode aplicar patches ou configurar regras de firewall para bloquear essa ameaça. O monitoramento contínuo desses registros é uma linha de defesa ativa contra ameaças cibernéticas. É um trabalho que exige atenção constante.
Além dos logs de acesso, logs de auditoria e logs de eventos de segurança do sistema operacional fornecem informações valiosas sobre quem fez o quê no sistema e quando. Isso é fundamental para a conformidade com regulamentações e para investigações forenses em caso de incidentes. Manter esses logs seguros e íntegros é igualmente importante; um atacante pode tentar apagar seus rastros alterando ou excluindo logs. Portanto, estratégias de armazenamento seguro e, idealmente, cópias externas dos logs são recomendadas. A segurança do seu servidor depende, em grande parte, da sua capacidade de monitorar e interpretar esses registros.
Como Visualizar e Interpretar Eventos de Servidor em Logs
Visualizar e interpretar eventos de servidor em logs pode parecer intimidante no início, mas com as ferramentas e o conhecimento certos, torna-se um processo gerenciável. Como mencionei, em Windows Server, o Event Viewer é o ponto de partida. Ele organiza os eventos em categorias claras (Application, Security, System, etc.), permitindo filtrar por data, hora, tipo de evento e gravidade. Cada evento possui um ID único e uma descrição detalhada que, muitas vezes, já oferece pistas sobre o que aconteceu.
No mundo Linux, a visualização geralmente envolve o uso de comandos de terminal. Ferramentas como tail, grep, less e awk são seus melhores amigos para navegar e filtrar arquivos em /var/log/. Por exemplo, você pode usar grep 'error' /var/log/syslog para encontrar todas as linhas que contêm a palavra
Dicas Extras: Truques que Fazem a Diferença na Hora de Analisar
Vamos combinar: teoria é legal, mas o que resolve mesmo são as dicas práticas. Anota essas que eu já testei:
- Padronize o formato dos seus registros desde o início. Use JSON estruturado para facilitar a busca e análise automática depois.
- Configure alertas inteligentes para erros críticos. Não espere para olhar manualmente; deixe o sistema te avisar.
- Faça uma limpeza periódica dos arquivos antigos. Logs acumulados podem consumir espaço em disco e atrapalhar a performance.
- Documente os códigos de erro customizados da sua aplicação. Crie um ‘dicionário’ interno para a equipe consultar rapidamente.
- Teste o pipeline de logs em ambiente de homologação antes de ir para produção. Evita surpresas desagradáveis.
Perguntas Frequentes sobre Registros de Servidor
Qual a diferença entre log de servidor e log de aplicação?
O registro do servidor monitora a infraestrutura (como uso de CPU e memória), enquanto o da aplicação foca no comportamento do software (erros de código e fluxos de usuário). Imagine que o primeiro cuida da ‘casa’ e o segundo, do que acontece dentro dela. Ambos são complementares para um diagnóstico completo.
Quanto custa implementar um sistema de log centralizado?
O custo varia muito, mas você pode começar com ferramentas open-source como Graylog ou ELK Stack, que são gratuitas. O investimento maior geralmente está no tempo de configuração e na infraestrutura para armazenar os dados. Para empresas, soluções pagas oferecem suporte e recursos avançados, mas o essencial você consegue sem gastar nada inicialmente.
Como configurar o log de acesso no Apache?
Edite o arquivo ‘httpd.conf’ ou ‘.htaccess’ e use a diretiva ‘CustomLog’ para definir o caminho e o formato. O formato comum é o ‘Combined’, que inclui IP, timestamp, método HTTP e código de status. Depois, reinicie o serviço para aplicar as mudanças. Fica tranquilo, a documentação oficial do Apache tem exemplos passo a passo que ajudam bastante.
Não Deixe esse Erro Custar Caro para Você
Pois é, ignorar os registros do seu servidor é como dirigir com os olhos vendados. Você aprendeu que eles são a chave para diagnosticar falhas, monitorar segurança e evitar prejuízos. De logs básicos em /var/log/ até ferramentas como Nagios, o poder está nas suas mãos.
Seu primeiro passo hoje? Abra os arquivos de log do seu sistema agora mesmo. Veja o que está acontecendo lá dentro. Identifique um padrão ou um aviso que você vinha ignorando.
Compartilha essa dica com quem também precisa parar de ‘apagar incêndio’ e começar a prevenir. E me conta nos comentários: qual foi o erro mais inesperado que você já encontrou analisando esses registros?


