

Você já se perguntou como o Google entende o que você quis dizer quando digita ‘melhores filmes de 2023’? O segredo está nos vetores de palavras, e o Word2Vec é a ferramenta que transforma texto em números que máquinas compreendem. Esqueça a ideia de que computadores leem como humanos: eles processam matemática pura.
O algoritmo Word2Vec, criado pelo Google em 2013, mapeia palavras para coordenadas numéricas que preservam relações semânticas. Isso significa que ‘gato’ e ‘felino’ ficam pertinhos no espaço vetorial, enquanto ‘cachorro’ fica mais distante. A mágica está na Hipótese Distribucional: palavras que aparecem em contextos similares têm significados próximos.
Como o Word2Vec aprende relações entre palavras: CBOW e Skip-gram
O Word2Vec opera com dois modelos principais: o CBOW (Continuous Bag of Words) e o Skip-gram. No CBOW, o algoritmo tenta adivinhar a palavra central a partir das palavras ao redor, como preencher a lacuna em ‘O ___ está latindo’. Já o Skip-gram faz o inverso: dada a palavra central, ele prevê o contexto, como gerar ‘cachorro’ e ‘latindo’ a partir de ‘animal’. Ambos são eficientes, mas o Skip-gram funciona melhor com conjuntos de dados pequenos.
Esses modelos geram word embeddings densos, ao contrário do One-Hot Encoding, que cria vetores enormes e esparsos. Com vetores de 100 a 300 dimensões, o Word2Vec captura analogias: ‘Rei’ – ‘Homem’ + ‘Mulher’ ≈ ‘Rainha’. Bibliotecas como Gensim em Python facilitam a implementação, e você pode treinar seu próprio modelo com textos em português em minutos.
Word2Vec: A Revolução dos Vetores de Palavras no PLN
Em 2013, o Google nos presenteou com o Word2Vec, um marco no Processamento de Linguagem Natural (PLN). Ele mudou a forma como as máquinas entendem a linguagem, transformando palavras em números com significado. Essa capacidade de gerar ‘word embeddings’ é a chave para capturar as nuances semânticas, fazendo com que termos como ‘casa’ e ‘lar’ fiquem próximos no espaço vetorial.
A genialidade do Word2Vec está na Hipótese Distribucional: palavras que aparecem juntas em contextos parecidos compartilham significados. É um aprendizado inteligente que reflete como nós, humanos, compreendemos o mundo. Essa abordagem não supervisionada e eficiente é a base para muitas inovações em IA que vemos hoje.
| Característica | Descrição |
|---|---|
| Desenvolvedor | |
| Ano de Lançamento | 2013 |
| Principal Inovação | Word Embeddings (vetores densos de palavras) |
| Princípio Teórico | Hipótese Distribucional |
| Modelos Arquiteturais | CBOW, Skip-gram |
| Vantagens | Captura semântica, eficiência computacional, aprendizado não supervisionado |
Word2Vec: O que são Word Embeddings
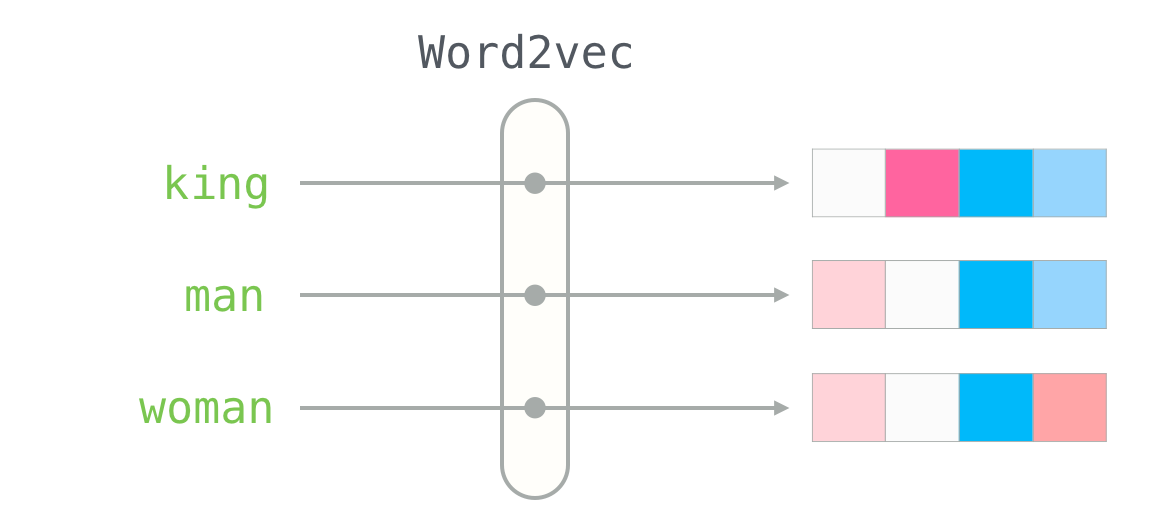
Os ‘word embeddings’ são a essência do Word2Vec. Pense neles como coordenadas em um mapa multidimensional onde cada palavra tem seu lugar. Palavras com significados próximos, como ‘feliz’ e ‘contente’, estarão geograficamente próximas nesse mapa. Essa representação numérica densa é muito mais poderosa que métodos antigos, como o One-Hot Encoding, que criavam vetores esparsos e pouco informativos sobre as relações entre as palavras.
Esses vetores não são apenas números aleatórios; eles codificam relações complexas. A proximidade entre vetores indica similaridade semântica, permitindo que algoritmos de machine learning para texto identifiquem padrões e entendam o contexto de forma mais eficaz. A construção desses vetores é um passo crucial no pré-processamento de texto para diversas tarefas de PLN.
CBOW: Predição de Palavras pelo Contexto
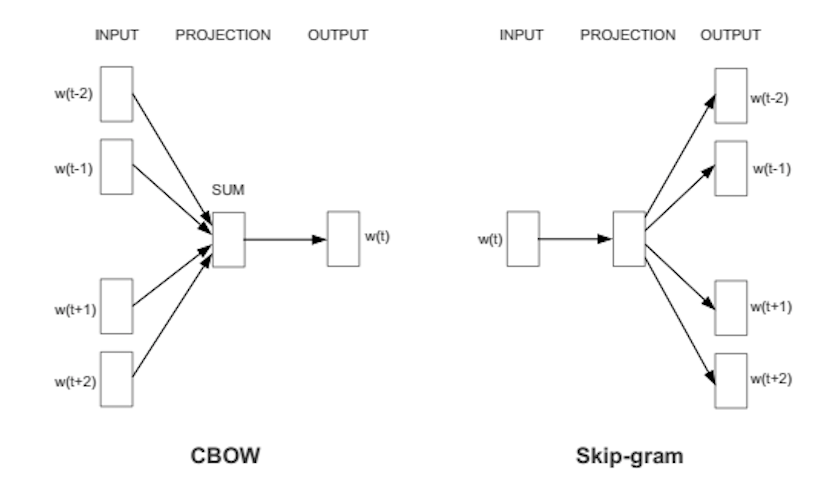
O modelo CBOW, ou Continuous Bag of Words, opera de maneira intuitiva. Ele pega um conjunto de palavras vizinhas (o contexto) e tenta prever qual seria a palavra central. É como se você visse as palavras ao redor de uma lacuna e tentasse adivinhar a palavra que falta ali. Esse processo de predição, repetido milhares de vezes com grandes volumes de texto, refina os vetores das palavras para que elas representem bem seus contextos típicos.
O CBOW é particularmente eficiente para prever palavras em contextos comuns, sendo uma escolha sólida para muitas aplicações de PLN.
Skip-gram: Contexto a partir da Palavra Alvo
Em contrapartida, o Skip-gram faz o caminho inverso. Dada uma palavra central, ele tenta prever as palavras que a cercam, ou seja, seu contexto. Se a palavra central for ‘banco’, o Skip-gram tentaria prever palavras como ‘dinheiro’, ‘sentar’, ‘rio’, dependendo do contexto original. Essa abordagem é conhecida por ser excelente em capturar relações mais sutis e é frequentemente preferida quando se lida com vocabulários menores ou dados mais esparsos.
A arquitetura do Skip-gram, embora pareça simples, é poderosa. Ao aprender a prever o contexto a partir da palavra, ele força os vetores a encapsularem informações semânticas ricas. Essa capacidade de generalização é um dos motivos pelos quais o Skip-gram é tão valorizado em tarefas que exigem um entendimento profundo da linguagem.
Hipótese Distribucional: Base do Word2Vec
A Hipótese Distribucional é o pilar filosófico do Word2Vec. Ela afirma que palavras que aparecem em contextos semelhantes tendem a ter significados parecidos. Essa ideia simples, mas profunda, é o que permite ao algoritmo aprender as relações semânticas. Ao analisar a frequência e o contexto de coocorrência das palavras em um corpus, o Word2Vec constrói representações vetoriais que refletem essa proximidade de significado.
Essa hipótese é fundamental para qualquer modelo de aprendizado de máquina para texto que busca entender a semântica. Ela valida a abordagem de que a distribuição de uma palavra em um texto é uma pista valiosa sobre seu significado. É por isso que o Word2Vec se tornou tão influente, fornecendo uma base sólida para a análise de similaridade semântica.
Pré-processamento de Texto para Word2Vec
Antes de alimentar o Word2Vec com dados, um bom pré-processamento de texto é essencial. Isso envolve etapas como tokenização (dividir o texto em palavras), remoção de stopwords (palavras comuns sem muito significado, como ‘o’, ‘a’, ‘de’), e lematização ou stemming (reduzir palavras às suas formas base). Um pré-processamento cuidadoso garante que o algoritmo aprenda com dados limpos e relevantes, otimizando a qualidade dos vetores gerados.
A qualidade dos seus ‘word embeddings’ depende diretamente da qualidade dos dados de entrada. Investir tempo em um pré-processamento robusto é crucial para obter resultados precisos em tarefas como análise de sentimentos ou sistemas de recomendação. É um passo que muitos negligenciam, mas que faz toda a diferença.
Similaridade Semântica com Vetores de Palavras
A grande sacada do Word2Vec é permitir a medição da similaridade semântica entre palavras. Como os vetores capturam significado, a distância entre eles no espaço vetorial reflete o quão semelhantes são as palavras. Podemos usar métricas como a similaridade de cosseno para quantificar essa relação. Isso abre portas para aplicações como encontrar sinônimos, agrupar termos relacionados ou até mesmo para a tarefa de similaridade entre títulos de produtos.
A capacidade de quantificar a similaridade semântica é um dos maiores trunfos do Word2Vec, impulsionando a inteligência de muitas aplicações.
Redes Neurais no Word2Vec: Arquitetura Simples
Embora o Word2Vec seja conhecido por sua eficiência, ele utiliza redes neurais em sua arquitetura. Tanto o CBOW quanto o Skip-gram empregam uma rede neural simples, com uma camada de entrada, uma camada oculta (que contém os vetores de palavras) e uma camada de saída. A magia acontece durante o treinamento, onde os pesos da camada oculta são ajustados para minimizar o erro de predição, resultando nos ‘word embeddings’ desejados. Essa arquitetura é um exemplo clássico de como redes neurais podem ser aplicadas de forma eficaz em PLN.
A simplicidade da arquitetura é enganosa; ela é projetada para ser computacionalmente eficiente, permitindo o treinamento em grandes datasets sem exigir recursos excessivos. Essa otimização é um dos legados do Word2Vec para o campo de redes neurais para PLN.
Aplicações Práticas do Word2Vec em PLN
O impacto do Word2Vec no mundo real é vasto. Ele é a espinha dorsal de sistemas de recomendação, ajudando a sugerir produtos ou conteúdos com base no histórico do usuário. Na análise de sentimentos, ele permite entender se um texto expressa uma opinião positiva ou negativa. Tradução automática, chatbots e sumarização de textos também se beneficiam enormemente de sua capacidade de entender a relação entre palavras.
A versatilidade do Word2Vec o torna uma ferramenta indispensável para desenvolvedores e pesquisadores em 2026. Bibliotecas como a Gensim em Python tornam sua implementação acessível, permitindo que qualquer um explore o poder dos vetores de palavras. Ele continua sendo um ponto de partida fundamental para quem trabalha com processamento de linguagem natural.
O Futuro do Word2Vec em 2026: Um Legado Duradouro
Em 2026, o Word2Vec não é apenas uma ferramenta, mas um legado. Embora modelos mais complexos como os Transformers tenham surgido, a simplicidade, eficiência e a compreensão fundamental que o Word2Vec trouxe para os ‘word embeddings’ continuam relevantes. Ele estabeleceu as bases para o que é possível em PLN, ensinando-nos o valor da representação vetorial densa e da captura de similaridade semântica.
Eu vejo o Word2Vec como um componente essencial em pipelines de PLN mais sofisticados, especialmente onde a eficiência computacional é crítica ou quando se trabalha com recursos limitados. Seu aprendizado não supervisionado e a capacidade de gerar insights a partir de texto bruto o mantêm como um favorito para muitas aplicações práticas. É uma tecnologia que moldou o campo e continua a inspirar novas abordagens.
A Arte de Vetorizar Palavras
- Para implementar Word2Vec com sucesso, foque na qualidade do corpus: textos limpos e contextualmente ricos geram embeddings mais precisos. A escolha entre CBOW e Skip-gram depende do tamanho do dataset — CBOW é mais rápido em corpora grandes, enquanto Skip-gram captura melhor relações com vocabulário raro.
- Utilize a biblioteca Gensim em Python para treinar modelos, ajustando hiperparâmetros como tamanho do vetor (dimensão 100-300) e janela de contexto (5-10 palavras). Pré-processe o texto com tokenização, remoção de stopwords e stemming para reduzir ruído e melhorar a representação semântica.
Perguntas Frequentes
O Word2Vec funciona para qualquer idioma?
Sim, desde que o corpus de treinamento seja representativo do idioma alvo. A qualidade dos embeddings depende da diversidade e do volume do texto utilizado.
Qual a diferença entre Word2Vec e GloVe?
Word2Vec aprende embeddings a partir de contextos locais (janelas de palavras), enquanto GloVe utiliza estatísticas globais de coocorrência da matriz inteira. Ambos são eficazes, mas Word2Vec é mais rápido para treinar em grandes corpora.
Como avaliar a qualidade dos embeddings gerados?
Use tarefas intrínsecas, como analogias (ex: ‘rei’ – ‘homem’ + ‘mulher’ ≈ ‘rainha’), e extrínsecas, como classificação de sentimentos. A proximidade entre vetores de sinônimos e a separação de antônimos indicam boa representação.
O Word2Vec continua sendo uma ferramenta essencial no PLN, combinando eficiência computacional com capacidade de capturar relações semânticas profundas. Sua implementação correta transforma texto bruto em representações vetoriais que alimentam sistemas de recomendação, análise de sentimentos e tradução automática.
Para dominar o Word2Vec, comece com um dataset pequeno e vá ajustando os parâmetros conforme os resultados. Explore bibliotecas como Gensim e TensorFlow para integrar embeddings em seus projetos de machine learning.
A evolução dos embeddings caminha para modelos contextuais como BERT, mas o Word2Vec permanece como base conceitual e prática. Dominar seus princípios oferece uma vantagem sólida para enfrentar desafios modernos de NLP.


