

Você busca otimizar seu trabalho com spark para processamento de big data? Imagina lidar com volumes massivos de dados em 2026, enfrentando gargalos que atrasam suas análises e decisões cruciais. Pois é, muitas empresas sofrem com a lentidão de ferramentas antigas. Mas a boa notícia é que existe uma solução poderosa e ágil. Neste post, eu vou te mostrar como o Apache Spark revoluciona o processamento de Big Data, transformando seus desafios em velocidade e eficiência.
“O Apache Spark pode ser até 100 vezes mais rápido que o MapReduce do Hadoop em operações na memória.”
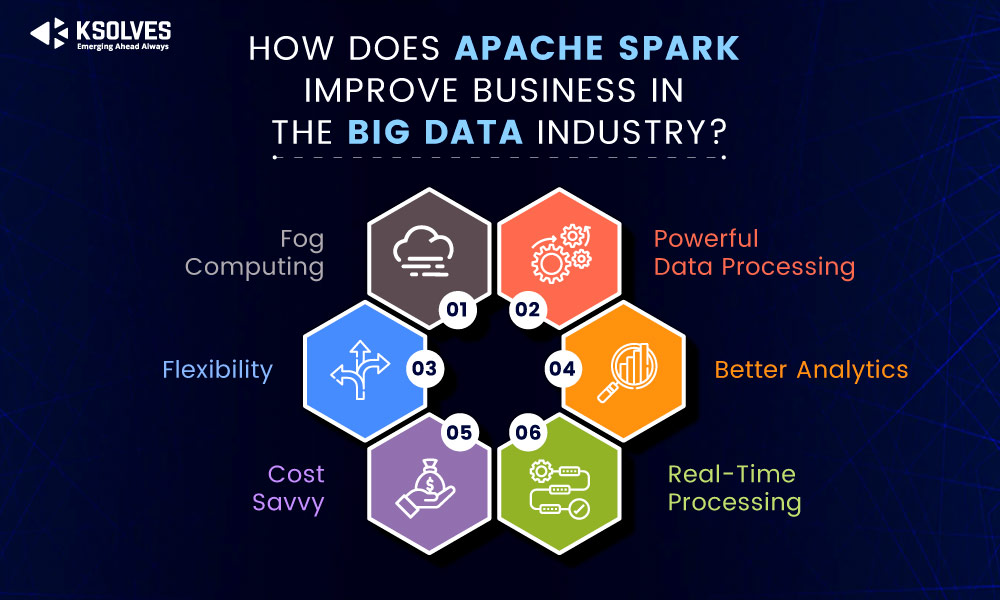
Por que o Apache Spark é a Ferramenta Indispensável para Processamento de Big Data em Alta Velocidade em 2026?
O Apache Spark se consolidou como o padrão ouro para quem lida com Big Data.
Ele entrega performance que deixa para trás soluções como o antigo MapReduce do Hadoop, rodando dados em memória.
Essa agilidade significa análises mais rápidas e insights valiosos em tempo real.
Além disso, o Spark unifica diversas tarefas: processamento em lote, consultas SQL, análise de streaming, machine learning e até grafos complexos.
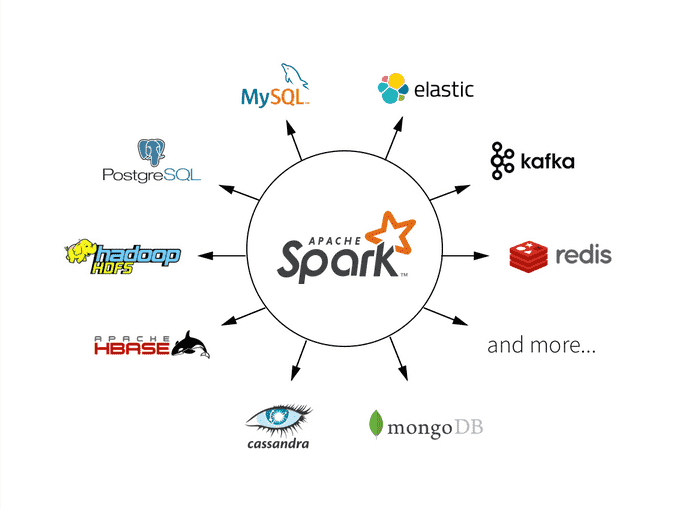
Você tem flexibilidade para usar Python, Scala, Java ou R, integrando tudo com HDFS, S3 e seus bancos NoSQL favoritos.
Apache Spark: Acelerando o Processamento de Big Data com Velocidade Espacial
Imagina só: você tem uma montanha de dados, e precisa tirar informações úteis dali o mais rápido possível. É aí que o Apache Spark entra em cena como o verdadeiro campeão do processamento distribuído de Big Data. Diferente de tecnologias mais antigas, como o MapReduce do Hadoop, que ficam gravando tudo no disco a cada passo, o Spark é genial porque trabalha direto na memória (RAM). Isso significa que ele pode ser até 100 vezes mais rápido em muitas operações. Essa velocidade é um divisor de águas, especialmente para aqueles algoritmos que precisam repetir a mesma conta várias vezes (algoritmos iterativos) ou quando você precisa de respostas quase em tempo real. Vamos combinar, isso muda o jogo!
| Característica | Descrição |
|---|---|
| Velocidade em Memória | Processamento direto na RAM, eliminando gargalos de disco. |
| Engine Unificada | Suporta batch, SQL, streaming, ML e grafos em um só lugar. |
| Flexibilidade de Linguagem | APIs em Python (PySpark), Scala, Java e R. |
| Ecossistema Integrado | Conecta com HDFS, S3, Azure Data Lake, Cassandra, MongoDB e mais. |
Ferramentas Essenciais para Dominar o Apache Spark
Apache Spark Core: O Coração da Máquina
O Spark Core é a base de tudo. É ele que cuida do gerenciamento de tarefas, agendamento e das operações básicas de I/O. Tudo o que os outros módulos fazem se apoia nele. É o motor que faz tudo funcionar de maneira distribuída e eficiente. Pense nele como o maestro da orquestra, garantindo que cada instrumento (módulo) toque na hora certa.
Spark SQL: Consultando Seus Dados com Maestria
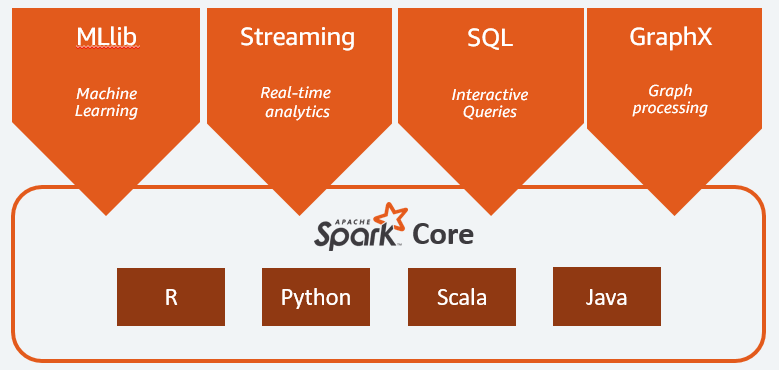
Se você gosta de trabalhar com dados estruturados e adora a praticidade do SQL, o Spark SQL é seu melhor amigo. Ele permite que você execute consultas SQL tradicionais ou use a abstração de DataFrames, que são superpoderosas e otimizadas para performance. É como ter um analista de dados experiente com você, pronto para desvendar tabelas complexas com consultas eficientes.
Spark Streaming: O Pulso do Tempo Real
O mundo hoje não para, e seus dados também não. O Spark Streaming entra para capturar e processar fluxos contínuos de dados em tempo real. Seja para monitorar logs de servidores, transações financeiras ou dados de sensores IoT, ele garante que você tenha a informação mais atualizada possível. Ele processa dados em pequenos lotes (micro-batches), o que traz uma latência baixa e resultados rápidos, essencial para tomar decisões ágeis.
MLlib: Inteligência Artificial em Escala

Para quem quer ir além da análise e começar a prever padrões ou classificar informações, a MLlib é a biblioteca de Machine Learning do Spark. Ela oferece um conjunto de algoritmos escaláveis e otimizados para rodar em ambientes distribuídos. Treinar modelos complexos em Big Data se torna muito mais viável com as ferramentas que a MLlib proporciona.
Preparando o Terreno para o Apache Spark
Antes de mergulhar de cabeça no Spark, é fundamental ter um ambiente preparado. Isso envolve desde a instalação do próprio Spark até a configuração das fontes de dados com as quais ele vai interagir. O Spark é flexível e não se prende a um único sistema de armazenamento; ele se integra maravilhosamente bem com soluções como o HDFS (o sistema de arquivos do Hadoop), serviços de nuvem como Amazon S3 ou Azure Data Lake, e até mesmo bancos de dados NoSQL como Cassandra e MongoDB. Certifique-se de que seu ambiente de rede e acesso a essas fontes de dados estejam configurados corretamente para garantir transferências de dados fluidas e seguras.
Processando Seus Dados com Apache Spark: Um Guia Passo a Passo
- Configurar o Ambiente Spark
Primeiro, você precisa ter o Spark instalado. Pode ser localmente para testes ou em um cluster distribuído para produção. Garanta que as variáveis de ambiente necessárias estejam definidas e que você tenha as dependências corretas para a linguagem que vai usar, como o PySpark para Python.
- Estabelecer a Conexão com a Fonte de Dados
Com o Spark pronto, o próximo passo é conectar-se aos seus dados. Seus dados podem estar em um arquivo CSV, Parquet, JSON, em um banco de dados relacional ou NoSQL, ou em um sistema de arquivos distribuído como o HDFS. O Spark oferece leitores específicos para cada tipo. Por exemplo, para ler um arquivo CSV, você usaria algo como `spark.read.csv(“caminho/para/seu/arquivo.csv”)`.
- Transformar e Manipular os Dados
Aqui é onde a mágica acontece. Você vai usar as APIs do Spark para limpar, filtrar, agrupar e transformar seus dados. Por exemplo, para selecionar colunas específicas ou filtrar linhas com base em uma condição, você usaria métodos como `.select()` e `.filter()`. É aqui que a velocidade do Spark em memória realmente brilha, permitindo manipulações complexas de forma ágil.
- Realizar Análises ou Executar Modelos
Dependendo do seu objetivo, você pode executar consultas SQL com o Spark SQL, aplicar algoritmos de Machine Learning com a MLlib, ou processar dados em tempo real com Spark Streaming. Para análises exploratórias, um simples `.show()` após as transformações pode ser suficiente para visualizar os resultados. Explore a documentação oficial para detalhes sobre cada módulo.
- Salvar os Resultados
Após processar e analisar seus dados, você precisará armazenar os resultados. O Spark permite salvar os dados transformados em diversos formatos e locais, seja de volta em um arquivo (CSV, Parquet, etc.), em um banco de dados ou em um sistema de armazenamento na nuvem como o Amazon S3.
Como Lidar com Erros Comuns no Apache Spark
Mesmo com toda essa potência, é normal encontrar alguns percalços. Um erro comum é o `OutOfMemoryError`, especialmente quando se trabalha com dados muito grandes e não se otimiza o uso da memória. Certifique-se de configurar corretamente a memória alocada para o executor do Spark (`spark.executor.memory`) e, se possível, particione seus dados de forma eficiente. Outro ponto é o desempenho abaixo do esperado; muitas vezes, isso está ligado a um join ineficiente entre DataFrames. Revisar estratégias de join e, em alguns casos, usar `broadcast joins` para tabelas menores pode fazer uma diferença brutal na performance. Entender o grau de paralelismo e como ele afeta suas operações também é crucial. E, claro, sempre verifique os logs do driver e dos executores para identificar a causa raiz dos problemas. A comunidade Spark é vasta, e fóruns como o Spark Discussion são ótimos para encontrar soluções.