

Seu interesse em saber o que é o Apache Spark é super válido, especialmente quando lidamos com o volume gigantesco de dados que vemos hoje. Muitas ferramentas prometem agilidade, mas acabam se perdendo em complexidade ou lentidão. Este artigo vai te mostrar o poder do Spark, como ele resolve esse gargalo e te prepara para o futuro dos dados, sem complicação.
“O Apache Spark é um motor de processamento de dados distribuído em memória, até 100x mais rápido que soluções baseadas em disco.”
O que é o Apache Spark e como ele funciona na prática
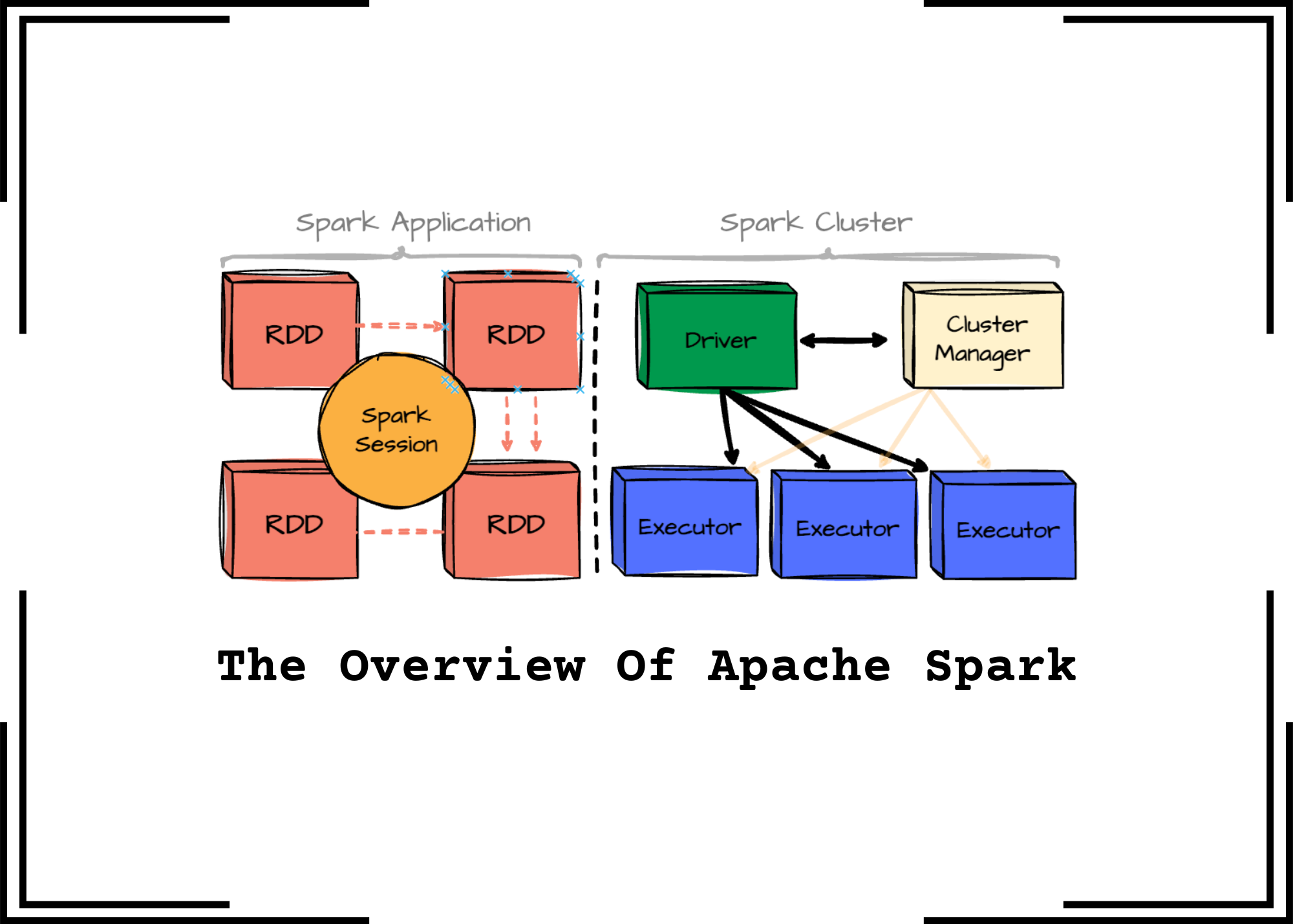
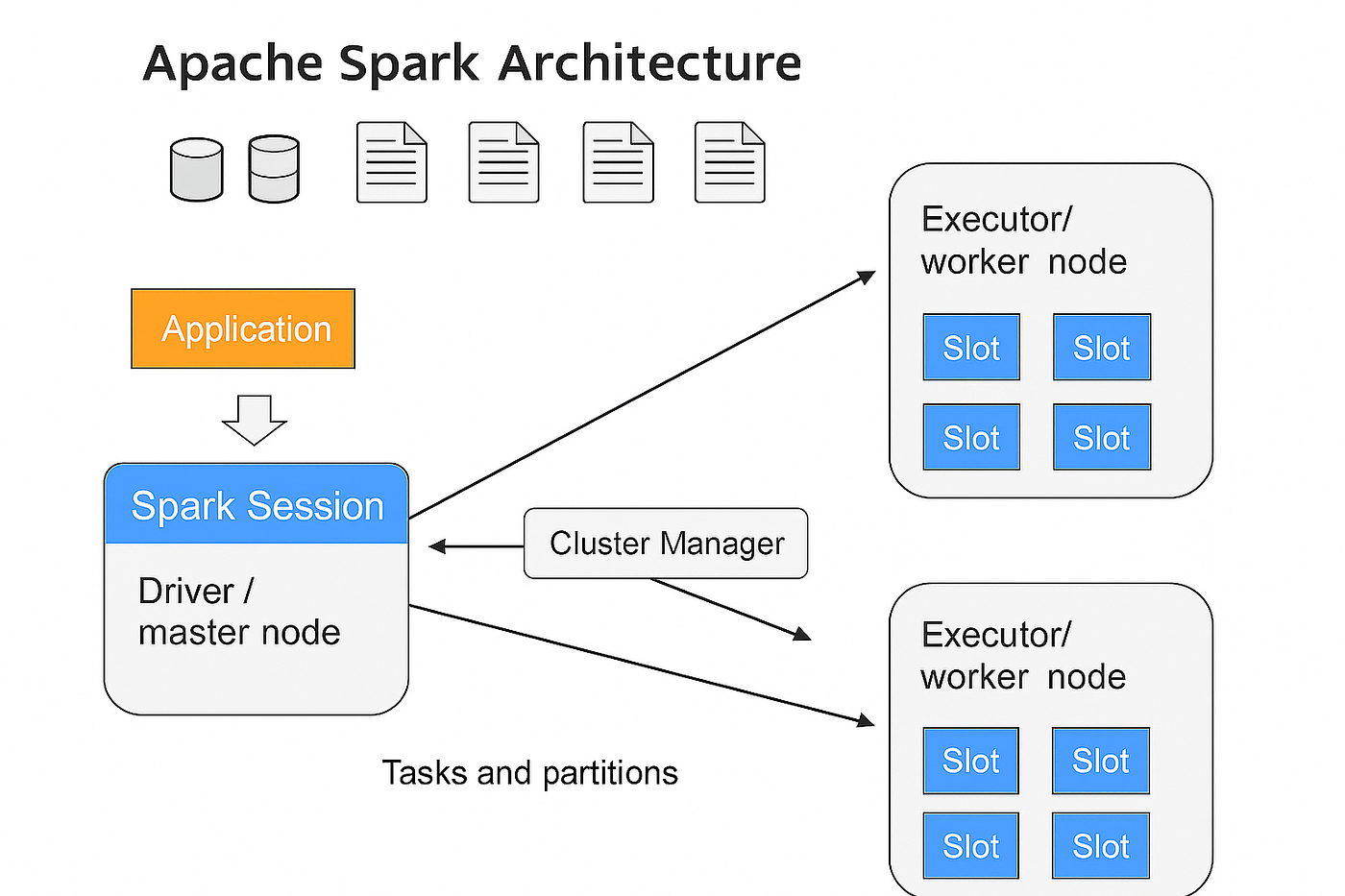
O Apache Spark é um motor de processamento distribuído de Big Data, projetado para ser rápido e versátil. Ele unifica o processamento de dados em lote (batch) e em tempo real (streaming) em uma única plataforma, utilizando cacheamento em memória e um otimizador de consultas avançado para acelerar as operações.
| Aspecto | Detalhe Técnico |
|---|---|
| Tipo de Processamento | Distribuído, em memória |
| Velocidade | Alta, devido ao cacheamento em memória |
| APIs Suportadas | Python (PySpark), Scala, Java, R, SQL |
| Uso Principal | Análise de Big Data, Machine Learning, Processamento de Grafos |
| Licença | Código Aberto (Apache License 2.0) |
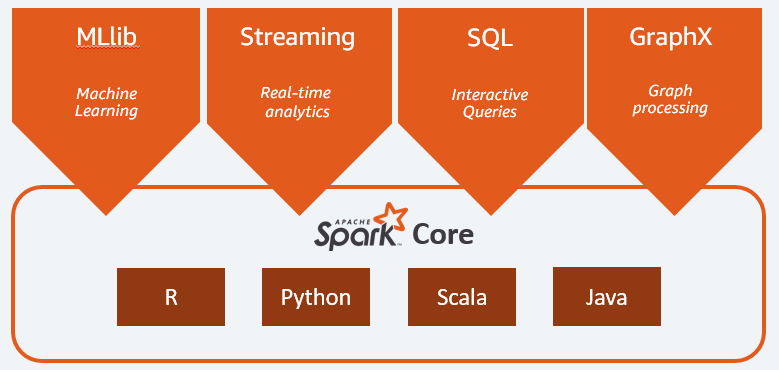
Vantagens, Desvantagens e Impacto Real do Apache Spark
- Vantagens: Velocidade superior em muitas cargas de trabalho comparado a MapReduce, flexibilidade com APIs multilíngues, unificação de processamento batch e streaming, ecossistema rico com bibliotecas para ML e grafos.
- Desvantagens: Pode consumir mais memória RAM, complexidade na configuração e otimização para iniciantes, custo de infraestrutura pode ser elevado para grandes clusters.
- Impacto Real: Permite análises mais rápidas e profundas em grandes volumes de dados, viabiliza a criação de aplicações de IA em tempo real e otimiza processos de negócios com insights mais ágeis.

Principais Características do Spark
O Spark oferece um conjunto robusto de funcionalidades para processamento de dados em larga escala.
- Gerenciamento de Tarefas: Execução otimizada de tarefas distribuídas com tolerância a falhas.
- Otimização de Consultas: O otimizador Catalyst melhora a performance de consultas SQL e DataFrames.
- Cache em Memória: Permite armazenar RDDs (Resilient Distributed Datasets) na memória para acesso rápido em iterações.
- Extensibilidade: Facilidade de integração com outros sistemas de Big Data.
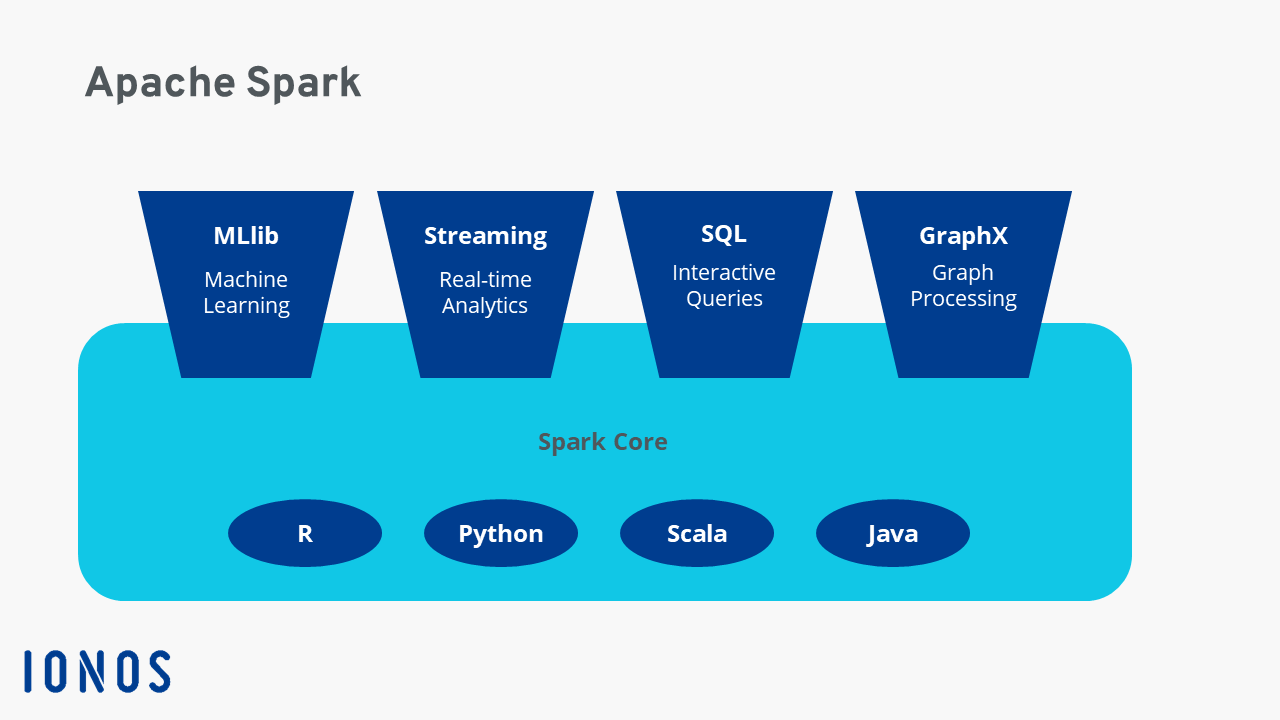
Componentes e Bibliotecas do Ecossistema Spark
O Spark é composto por diversos módulos que atendem a diferentes necessidades de processamento de dados.
- Spark Core: A base do sistema, responsável pelo agendamento, gerenciamento de memória e pelas operações de I/O.
- Spark SQL: Para trabalhar com dados estruturados e semiestruturados usando SQL e DataFrames.
- Spark Streaming: Processamento de fluxos de dados em tempo real.
- MLlib: Biblioteca para Machine Learning, com algoritmos escaláveis.
- GraphX: Para processamento e análise de grafos.
Spark SQL para Dados Estruturados
Facilita a análise de dados estruturados e semiestruturados através de consultas SQL e da API DataFrame.
- Composição/Material: Utiliza a API DataFrame e otimizador Catalyst.
- Indicação de Uso: Análise de logs, dados de vendas, informações de clientes em formato tabular.
- Diferencial: Performance otimizada para consultas e integração com diversas fontes de dados.

Spark Streaming para Dados em Tempo Real
Permite o processamento de fluxos de dados contínuos com baixa latência.
- Composição/Material: Processa dados em micro-lotes (discretized streams).
- Indicação de Uso: Monitoramento de redes sociais, detecção de fraudes em tempo real, análise de dados de sensores.
- Diferencial: Unifica o processamento batch e streaming, simplificando a arquitetura.
MLlib: Machine Learning Escalável com Spark
Oferece uma biblioteca de algoritmos de Machine Learning projetada para escalabilidade em Big Data.
- Composição/Material: Algoritmos de classificação, regressão, clustering, filtragem colaborativa.
- Indicação de Uso: Construção de modelos preditivos, sistemas de recomendação, segmentação de clientes.
- Diferencial: Escalabilidade para grandes datasets e integração direta com o ecossistema Spark.
GraphX: Análise de Grafos no Spark
Ferramenta para processamento e análise de dados em formato de grafo.
- Composição/Material: API para manipulação de grafos e algoritmos como PageRank.
- Indicação de Uso: Análise de redes sociais, detecção de comunidades, sistemas de recomendação baseados em conexões.
- Diferencial: Desempenho otimizado para operações em grafos distribuídos.

Uso Profissional e Mercado de Trabalho para Spark
O conhecimento em Apache Spark é altamente valorizado no mercado de trabalho de Big Data e Ciência de Dados.
- Cargos Comuns: Engenheiro de Dados, Cientista de Dados, Analista de Big Data.
- Ferramentas Relacionadas: Hadoop, Kafka, Hive, Flink.
- Oportunidades: Centenas de vagas disponíveis no Brasil em plataformas como LinkedIn e Indeed.
Preço Médio e Vale a Pena? (Mercado 2026)
O Apache Spark é um projeto de código aberto, o que significa que o software em si é gratuito. O custo associado ao Spark está na infraestrutura necessária para executá-lo (servidores, nuvem) e na expertise da equipe para configurá-lo e otimizá-lo. Para empresas que lidam com grandes volumes de dados e necessitam de processamento rápido e análises complexas, o investimento em Spark, seja em infraestrutura on-premise ou em serviços de nuvem gerenciados (como AWS EMR, Google Cloud Dataproc, Azure HDInsight), é altamente justificável. O retorno vem da capacidade de extrair insights valiosos, inovar em produtos e serviços baseados em dados e otimizar operações de forma eficiente. A demanda por profissionais qualificados em Spark continua alta, indicando seu valor estratégico no mercado atual e futuro.
Dicas Extras
- Otimize o Cache: Lembre-se que o Spark usa cache em memória. Use-o a seu favor para acelerar processamentos repetitivos. Libere memória quando não precisar mais de um RDD ou DataFrame.
- Monitore seus Jobs: A interface de usuário do Spark (geralmente na porta 4040) é sua melhor amiga. Use-a para entender gargalos, identificar tarefas lentas e otimizar a alocação de recursos.
- Escolha a Linguagem Certa: Para tarefas mais interativas e análise de dados, PySpark é excelente. Para performance máxima e sistemas complexos, Scala pode ser a melhor opção. O SQL é ideal para quem já trabalha com bancos de dados.
- Entenda o Lazy Evaluation: O Spark só executa as operações quando uma ação é chamada. Isso permite otimizações, mas é crucial entender o fluxo para depurar problemas.
- Gerencie Dependências: Em ambientes distribuídos, garantir que todas as máquinas tenham as mesmas versões de bibliotecas é fundamental. Use ferramentas de gerenciamento de pacotes.
Dúvidas Frequentes
O que é o Apache Spark e por que ele é tão rápido?
O Apache Spark é um motor de processamento distribuído de código aberto, projetado para ser rápido e escalável. Sua velocidade vem principalmente do uso de cacheamento em memória, que evita a necessidade de ler dados do disco repetidamente, e de um otimizador de consultas inteligente que planeja a execução das tarefas de forma eficiente. Ele unifica o processamento batch e em tempo real em uma única plataforma.
Quais são as principais ferramentas do ecossistema Spark?
O Spark oferece um conjunto robusto de ferramentas. O Spark SQL permite trabalhar com dados estruturados usando SQL ou APIs de DataFrame. O Spark Streaming lida com processamento de dados em tempo real. A MLlib é uma biblioteca poderosa para Machine Learning, e o GraphX é focado em análises de grafos. Essas ferramentas, juntas, cobrem uma vasta gama de necessidades em Big Data.
Spark vs. Hadoop MapReduce: Qual a diferença?
A principal diferença é a velocidade e a forma como processam os dados. O Hadoop MapReduce lê e escreve dados no disco entre as etapas, o que o torna mais lento. O Spark, por outro lado, mantém os dados na memória sempre que possível, o que acelera drasticamente os processamentos, especialmente para workloads interativas e iterativas. O Spark também oferece uma API mais rica e unificada.
Conclusão
Dominar o Apache Spark abre um leque enorme de oportunidades no universo de Big Data. Sua capacidade de processar grandes volumes de dados com agilidade e sua flexibilidade em lidar com diferentes tipos de análise o tornam uma ferramenta indispensável. Explore as funcionalidades do Spark Streaming para entender processamento de dados em tempo real e mergulhe na MLlib para construir modelos de Machine Learning avançados. A jornada no mundo do Spark é contínua e recompensadora.