

Você já se perguntou o que é normalização de dados e por que ela é tão crucial? No mundo atual, em 2026, lidar com montanhas de informações, sejam elas em bancos de dados robustos ou em conjuntos complexos para análise, é um desafio diário. Muitas vezes, a desorganização e a inconsistência sabotam seus projetos, tornando tudo mais lento e propenso a erros. Mas calma, a normalização de dados é a chave para descomplicar essa bagunça, garantindo que suas informações trabalhem a seu favor. Neste post, eu vou te mostrar exatamente como isso funciona e os benefícios que você não pode ignorar.
“A normalização em Ciência de Dados ajusta a escala de valores numéricos para um intervalo comum, geralmente entre 0 e 1.”
Como o que é normalização de dados resolve problemas práticos em bancos de dados e ciência de dados?
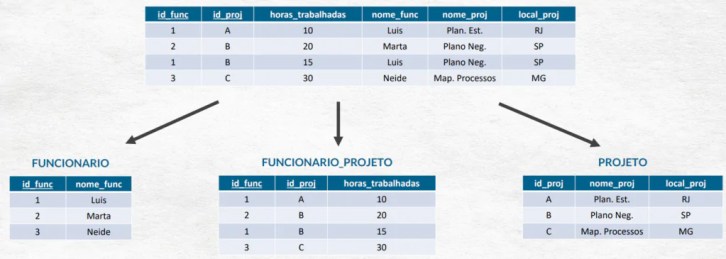
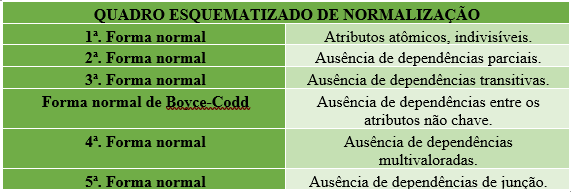
Basicamente, normalizar dados tem dois grandes focos. No universo dos bancos de dados, é o método para organizar suas tabelas. O objetivo é eliminar repetição desnecessária e garantir que cada informação seja única e confiável. Isso é feito através de um conjunto de regras chamadas Formas Normais, como a 1FN, 2FN e 3FN.
Já na Ciência de Dados e Estatística, a normalização é uma etapa essencial de pré-processamento. Ela ajusta seus números para que todos fiquem numa escala parecida, geralmente entre 0 e 1. Assim, você garante que nenhuma variável, por ter um valor absoluto maior, domine o resultado apenas por isso.
Isso é fundamental para que algoritmos de Machine Learning, como o KNN ou o SVM, funcionem com precisão. Sem essa equalização, eles podem interpretar mal a importância das suas variáveis.
O que é normalização de dados e por que ela é crucial para organizar informações em bancos de dados?
Pois é, a normalização de dados, no contexto de bancos de dados relacionais, é um processo fundamental. Pense nela como um conjunto de regras rigorosas que aplicamos para estruturar nossas informações da melhor maneira possível. O objetivo principal aqui é duplo e diretamente ligado à eficiência e confiabilidade do seu banco. Primeiro, eliminar a redundância. Isso significa garantir que a mesma informação não fique espalhada em vários lugares. Quando você não tem dados repetidos, o espaço de armazenamento é otimizado e a chance de erros diminui drasticamente. Segundo, e tão importante quanto, é garantir a integridade dos dados. Ao evitar a repetição e organizar tudo de forma lógica, as operações de atualização, exclusão e inserção de novas informações se tornam muito mais seguras. Você previne o que chamamos de anomalias, que são aquelas inconsistências chatas que aparecem quando uma atualização em um lugar não reflete em outro. Esse processo é dividido em etapas, conhecidas como Formas Normais (1FN, 2FN, 3FN, e assim por diante). Cada uma dessas formas resolve um tipo específico de dependência inadequada, refinando a estrutura do seu banco de dados.
| Objetivo Principal | Benefícios Diretos | Processo |
|---|---|---|
| Eliminar Redundância | Otimiza espaço, reduz erros de inconsistência | Estruturação baseada em Formas Normais (1FN, 2FN, 3FN) |
| Garantir Integridade dos Dados | Facilita atualizações, exclusões e inserções sem anomalias | Organização lógica para prevenir inconsistências |
Ferramentas e Materiais Essenciais para Compreender a Normalização

Aprofundando com a Documentação do Google for Developers
Para quem quer entender as bases e como aplicar, o material do Google for Developers é um ponto de partida sólido. Eles costumam detalhar as técnicas e as razões por trás delas, como no caso do dimensionamento de dados, que é uma faceta da normalização aplicável a machine learning. A clareza na explicação dos métodos comuns, como o dimensionamento linear (Min-Max), escala Z e dimensionamento logarítmico, é um grande diferencial.
Explorando Recursos no YouTube para Visualizar Conceitos

O YouTube se tornou uma plataforma incrível para aprender tecnologia. Você encontra conteúdos que vão desde o básico da normalização de dados em bancos relacionais até exemplos práticos. Para quem tem uma abordagem mais visual, a explicação das Formas Normais (1FN, 2FN, 3FN) através de exemplos concretos ajuda demais a fixar o conceito. Vi muitos tutoriais que desmistificam a aplicação das regras, mostrando como um banco de dados mal estruturado pode causar dores de cabeça.
Preparando seu Ambiente para a Normalização de Dados
Antes de sair aplicando as regras de normalização, é essencial ter clareza sobre o seu objetivo. Você está focado em organizar um banco de dados relacional para uma aplicação, ou está pensando em preparar dados para um modelo de inteligência artificial? Cada cenário exige um olhar um pouco diferente. Se for para banco de dados, ferramentas como MySQL, PostgreSQL ou SQL Server são o seu playground. Se o foco for IA, você vai trabalhar mais de perto com bibliotecas em Python, como Pandas e Scikit-learn, que facilitam a manipulação e o escalonamento dos dados.
Como Fazer a Normalização de Dados em um Banco de Dados Relacional Passo a Passo

Identifique as Dependências e Redundâncias

Referência: www.alura.com.br O primeiro passo é analisar sua estrutura de dados atual. Observe quais informações se repetem desnecessariamente e quais atributos dependem de outros de forma inadequada. Por exemplo, se você tem o nome do cliente repetido em várias tabelas de pedidos em vez de em uma única tabela de clientes, isso é um sinal claro de redundância. Essa análise inicial é crucial para saber por onde começar.
Aplique a Primeira Forma Normal (1FN)
Certifique-se de que cada coluna contenha valores atômicos (indivisíveis) e que não existam grupos repetidos de colunas. Por exemplo, se você tem uma coluna `telefones` que armazena múltiplos números separados por vírgula, a 1FN pede que cada número tenha sua própria linha ou coluna dedicada. O objetivo é ter um conjunto de colunas onde cada célula tem um único valor.
Aplique a Segunda Forma Normal (2FN)
Para que uma tabela esteja em 2FN, ela precisa primeiro estar em 1FN e, adicionalmente, todos os atributos não-chave devem depender completamente da chave primária. Isso é especialmente relevante para tabelas com chaves primárias compostas (formadas por mais de uma coluna). Se você tem, por exemplo, uma tabela onde `(ID_Pedido, ID_Produto)` é a chave primária e uma coluna como `Nome_Produto` está presente, ela só depende de `ID_Produto`, não da chave composta inteira. Nesse caso, você deve mover `Nome_Produto` para uma tabela de produtos separada.
Aplique a Terceira Forma Normal (3FN)
Após atender aos requisitos da 2FN, a 3FN exige que não existam dependências transitivas. Uma dependência transitiva ocorre quando um atributo não-chave depende de outro atributo não-chave, em vez de depender diretamente da chave primária. Por exemplo, em uma tabela de `Funcionários` com `ID_Funcionario` (chave primária), `Nome_Funcionario` e `ID_Departamento`, se `Nome_Departamento` estiver na mesma tabela, e `ID_Departamento` determina `Nome_Departamento`, então `Nome_Departamento` tem uma dependência transitiva sobre `ID_Funcionario`. A solução é criar uma tabela separada para `Departamentos`, contendo `ID_Departamento` e `Nome_Departamento`.
Refine e Verifique Continuamente
Após aplicar as formas normais, é fundamental revisar a estrutura. Verifique se as remoções de redundância foram eficazes e se a integridade dos dados foi mantida. Em alguns casos, para otimizar o desempenho de consultas específicas, pode ser necessário desnormalizar parcialmente alguns dados, mas isso deve ser uma decisão consciente e baseada em análise. A normalização não é um evento único, mas um processo contínuo de manutenção.
Como Consertar Erros Comuns na Aplicação da Normalização
Um erro frequente é o excesso de normalização, onde a estrutura fica tão dividida que as consultas se tornam lentas devido a muitas junções (JOINs). Se você se deparar com isso, analise o impacto no desempenho. Às vezes, é mais vantajoso criar uma visão (VIEW) ou até mesmo reintroduzir cuidadosamente alguma redundância controlada, como sugerido em algumas otimizações que você pode encontrar explorando o Google for Developers para entender as melhores práticas. Outro ponto de atenção é confundir normalização de banco de dados com a normalização de dados usada em Machine Learning, que é mais sobre ajustar escalas. Para isso, o material sobre como trabalhar com dados no Google AI pode ser muito útil, mostrando técnicas como o dimensionamento linear (Min-Max) e o escalonamento Z. Lembrar que muitos algoritmos de ML, como o KNN e SVM, se beneficiam enormemente dessa normalização de escala, pois cálculos de distância são afetados por valores em magnitudes diferentes. Explorar o aprendizado na plataforma Google Search também pode trazer insights sobre como estruturar e apresentar informações de forma otimizada para buscas e processamento.
Dicas Essenciais de Normalização de Dados
Para turbinar seus projetos, anote aí:
- Entenda o seu dado: Antes de sair normalizando, veja se faz sentido para o seu problema. Nem sempre é o caminho.
- Conheça os algoritmos: Algoritmos sensíveis à escala, como KNN e SVM, vão agradecer a normalização. Outros, como árvores de decisão, nem ligam tanto.
- Padronize o intervalo: A maioria dos métodos joga os dados entre 0 e 1. Fica mais fácil comparar e processar.
- Cuidado com outliers: Valores extremos podem distorcer o escalonamento Min-Max. Considere abordagens robustas se eles forem um problema.
- Valide seus resultados: Após normalizar, teste seus modelos. Veja se o desempenho melhorou como esperado.
- Use bibliotecas: Em Python, o Scikit-learn tem tudo que você precisa:
MinMaxScalereStandardScalerfacilitam demais.
FAQ: Normalização de Dados na Prática
- Por que normalizar dados em Machine Learning?
- Principalmente para que variáveis com escalas diferentes não influenciem desproporcionalmente os algoritmos. É sobre dar pesos justos a cada feature.
- Qual a diferença entre Normalização e Padronização (Standardization)?
- A normalização (Min-Max) ajusta os dados para um intervalo fixo, geralmente 0 a 1. A padronização (Z-score) transforma os dados para terem média 0 e desvio padrão 1. Cada um serve a um propósito.
- Normalizar sempre melhora o modelo?
- Não necessariamente. Depende muito do algoritmo e da natureza dos seus dados. Testar é fundamental.
- Posso normalizar dados categóricos?
- A normalização que falamos aqui é para dados numéricos. Dados categóricos precisam de outras técnicas de pré-processamento, como one-hot encoding.
- E se eu tiver dados negativos?
- O escalonamento Min-Max, por exemplo, lida bem com eles, ajustando-os dentro do intervalo definido. O Z-score também é projetado para isso.
Conclusão: A Normalização como Aliada Estratégica
Pois é, a normalização de dados não é só um passo técnico, é uma jogada estratégica. Seja para organizar a casa em um banco de dados ou para dar um gás nos seus modelos de Machine Learning, ela garante que suas informações sejam tratadas com a importância que merecem. Aplicar essas técnicas corretamente significa modelos mais eficientes, resultados mais confiáveis e, no fim das contas, decisões melhores. Vamos combinar, otimizar seu fluxo de dados é um ganho certo!