

Você já se pegou tomando decisões que pareciam apostas no escuro, desejando ter um mapa para o sucesso? Pois é, no mundo da inteligência artificial, o **algoritmo q learning** é exatamente esse mapa. Ele resolve um dilema comum: como um sistema pode aprender a fazer as melhores escolhas em um ambiente complexo, sem um guia passo a passo? Este artigo vai te mostrar como essa ferramenta poderosa te ajuda a otimizar suas decisões, aprendendo com a experiência, assim como nós fazemos. Prepare-se para entender como a tecnologia está aprendendo a ser mais esperta, decisão por decisão.
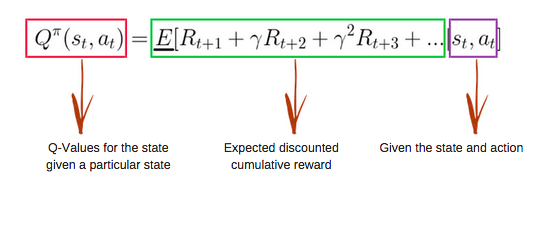
“O Q-learning utiliza uma tabela Q para armazenar os valores de ‘qualidade’ para cada par estado-ação, que são atualizados utilizando a equação de Bellman.”
Como exatamente o algoritmo q learning ensina uma máquina a tomar as melhores decisões do mercado em 2026?
Imagina ter um assistente digital que aprende com cada interação, aprimorando suas sugestões. O algoritmo q learning faz exatamente isso. Ele permite que um programa de computador, um ‘agente’, explore um ambiente, aprenda com os resultados de suas ações e, gradualmente, descubra qual caminho leva às maiores recompensas. Fica tranquila, não é mágica, é matemática aplicada. Ele funciona como um jogo de tentativa e erro inteligente. O agente recebe uma ‘recompensa’ quando faz algo bom e uma ‘penalidade’ quando erra. Com o tempo, ele aprende a associar ações específicas a resultados positivos em diferentes situações.
Essa capacidade de aprender sem um roteiro pré-definido é o que chamamos de ‘model-free’. A beleza do q learning está justamente em sua flexibilidade para se adaptar a cenários novos e imprevisíveis, algo essencial no dinâmico mundo de 2026. Ele não precisa conhecer todas as regras do jogo de antemão para se tornar um mestre.
O que é o Algoritmo Q-Learning? A Regra de Ouro do Aprendizado por Reforço
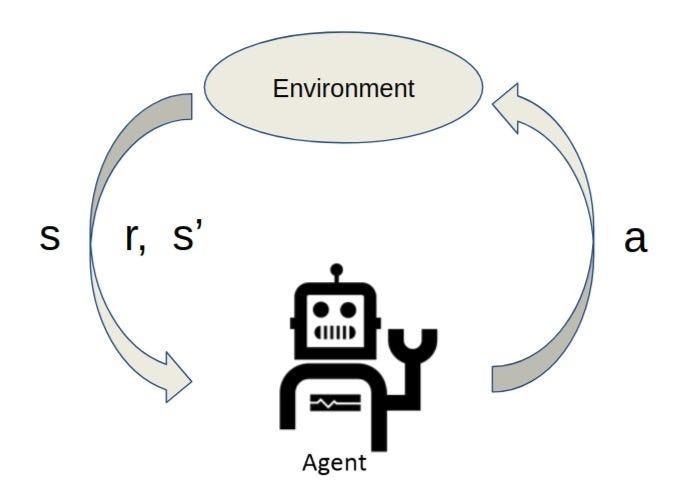
Imagina que você quer ensinar um robô a andar em um labirinto, certo? O Q-Learning é exatamente isso: um método inteligente de aprendizado por reforço que permite a um agente (nosso robô, por exemplo) aprender a tomar as melhores decisões em qualquer situação, mesmo sem um mapa prévio. Ele aprende na raça, por tentativa e erro, buscando sempre a maior recompensa acumulada ao longo do tempo. É um algoritmo do tipo ‘model-free’, ou seja, ele não precisa conhecer as regras completas do ambiente de antemão. O segredo está no ‘Q-value’, que é basicamente o valor que o algoritmo atribui a uma ação específica quando o agente está em um determinado estado. Quanto maior esse valor, melhor a ação.
| Conceito | Descrição |
|---|---|
| Agente | Entidade que interage com o ambiente e toma decisões. |
| Ambiente | O cenário onde o agente opera. |
| Estado (s) | A situação atual do ambiente percebida pelo agente. |
| Ação (a) | Uma das escolhas que o agente pode fazer em um determinado estado. |
| Recompensa (r) | Um sinal numérico que o ambiente fornece após uma ação, indicando se foi boa ou ruim. |
| Q-value (Q(s,a)) | O valor estimado da qualidade de tomar a ação ‘a’ no estado ‘s’. |
| Tabela Q | Estrutura (geralmente uma matriz) que armazena os Q-values para todos os pares estado-ação. |
Ferramentas e Materiais Essenciais para Dominar o Q-Learning
Python com Bibliotecas de Machine Learning (NumPy, SciPy)
Para colocar o Q-Learning em prática, a linguagem Python é quase um padrão. Bibliotecas como NumPy são fundamentais para manipular as tabelas Q de forma eficiente. Se você está começando, recomendo focar nos tutoriais básicos de NumPy; eles facilitam muito a vida na hora de criar e atualizar essas tabelas, que são o coração do algoritmo.
Ambientes de Simulação (Gymnasium, PyBullet)
Não dá para testar um robô no mundo real logo de cara, né? Ambientes de simulação como o Gymnasium (antigo OpenAI Gym) ou PyBullet são perfeitos para isso. Eles fornecem cenários controlados onde seu agente pode errar à vontade e aprender sem consequências. Pense no Gymnasium como um playground para seus algoritmos de aprendizado por reforço, com diversos desafios prontos para serem explorados.
Frameworks de Deep Learning (TensorFlow, PyTorch) para Deep Q-Learning
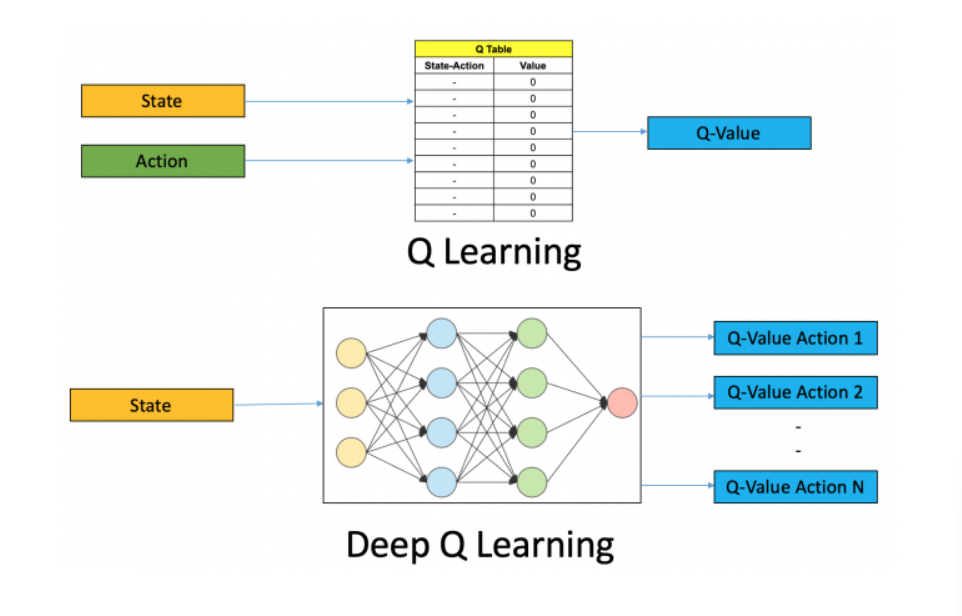
Quando o número de estados e ações fica gigantesco, como em jogos com gráficos de alta resolução, o Q-Learning tradicional (tabular) não dá conta. Aí entra o Deep Q-Learning, que usa redes neurais para estimar os Q-values. Se você vai por esse caminho, TensorFlow ou PyTorch são as pedidas. Eu acho que o PyTorch tem uma curva de aprendizado um pouco mais amigável para quem está começando com redes neurais, mas ambos são poderosíssimos.
Plataformas de Cursos Online (Coursera, Udacity)

Para ter uma base teórica sólida e ver exemplos práticos, plataformas como Coursera e Udacity oferecem cursos excelentes sobre aprendizado de máquina e aprendizado por reforço. Muitas vezes, eles têm até projetos guiados que usam o Q-Learning, o que ajuda muito a fixar o conteúdo. Vale a pena conferir os cursos de universidades renomadas que estão disponíveis lá.
Preparação para o Sucesso com o Algoritmo Q-Learning
Antes de mergulhar de cabeça, é crucial ter uma base sólida em alguns conceitos. A matemática por trás, especialmente o cálculo de probabilidades e a álgebra linear, vai te dar a confiança necessária para entender o que está acontecendo ‘por baixo dos panos’. Além disso, ter familiaridade com programação, especialmente em Python, é fundamental. Pense nisso como construir a fundação antes de erguer a casa; quanto mais forte a base, mais alto você pode construir.
Como Implementar o Q-Learning Passo a Passo
-
Inicialização da Tabela Q
O primeiro passo é criar a Tabela Q. Geralmente, ela é uma matriz onde as linhas representam os estados e as colunas representam as ações possíveis. Todos os valores dessa tabela são inicializados com zero ou com números arbitrários pequenos. Pense nisso como dar ao seu agente um ponto de partida cego.
-
Observação do Estado Atual
O agente observa o estado em que se encontra no ambiente. Isso é o que ele ‘vê’ ou percebe sobre a situação atual.
-
Seleção da Ação (Estratégia ϵ-greedy)
Aqui entra um equilíbrio crucial: exploração vs. explotação. Usamos a estratégia ϵ-greedy: com uma alta probabilidade (1-ϵ), o agente escolhe a ação que ele acredita ser a melhor (baseado nos Q-values atuais – explotação). Mas, com uma baixa probabilidade (ϵ), ele escolhe uma ação aleatória para descobrir novas possibilidades (exploração). Isso evita que o agente fique preso em uma solução subótima. A taxa ϵ geralmente diminui com o tempo, à medida que o agente aprende mais.
-
Execução da Ação e Coleta de Feedback
O agente executa a ação escolhida no ambiente. Como resposta, ele recebe duas coisas: uma recompensa (r) – que pode ser positiva ou negativa – e o novo estado (s’) para o qual o ambiente transitou.
-
Atualização da Tabela Q (Equação de Bellman)
Este é o momento chave do aprendizado. O valor na Tabela Q para o par estado-ação executado é atualizado usando a famosa Equação de Bellman. A ideia é que o valor de uma ação em um estado seja atualizado com base na recompensa imediata recebida mais o valor descontado da melhor ação possível no próximo estado. A fórmula é:
Q(s,a) ← Q(s,a) + α[r + γ max Q(s',a') - Q(s,a)]. Aqui,α(alfa) é a taxa de aprendizado, definindo o quanto a nova informação substitui a antiga, eγ(gama) é o fator de desconto, que determina a importância das recompensas futuras. Esses parâmetros são cruciais para a convergência do algoritmo. -
Repetição do Processo
Os passos de 2 a 5 são repetidos por muitas iterações (ou episódios). A cada ciclo, a Tabela Q vai se tornando uma representação mais precisa dos valores ótimos para cada estado-ação, guiando o agente para a maximização de recompensas. Essa iteração contínua é o que permite ao agente aprender estratégias complexas, como visto em exemplos de robótica e jogos.
Como Corrigir Erros Comuns no Q-Learning
Pois é, nem tudo são flores. Um erro comum é a convergência lenta. Se seu agente demora demais para aprender, verifique a taxa de aprendizado (α) e o fator de desconto (γ). Valores muito baixos de α ou γ podem desacelerar o aprendizado. Outro problema é o ciclo infinito em alguns ambientes. Isso pode acontecer se a estratégia ϵ-greedy não estiver bem calibrada ou se o agente não estiver explorando o suficiente. Diminuir α com o tempo e garantir que γ seja próximo de 1 pode ajudar. Em cenários com muitos estados, como em sistemas de sistemas de recomendação complexos, a Tabela Q pode ficar enorme e inviável. Nesses casos, a solução é migrar para o Deep Q-Learning, usando redes neurais para aproximar os valores, como explicado em materiais da USP sobre o tema. Fique atento também a recompensas mal definidas; se o feedback do ambiente não for claro ou for esparso demais, o agente terá dificuldade em aprender a política correta.
Dicas de Ouro para Usar o Q-Learning
Olha, para você tirar o máximo proveito do Q-Learning, eu tenho algumas sacadas que aprendi na raça:
- Comece Simples: Não se afogue em complexidade logo de cara. Comece com ambientes pequenos, com poucos estados e ações. Isso te ajuda a entender a dinâmica sem se perder. Depois, vá escalando.
- Ajuste Fino dos Parâmetros (α e γ): Essa é a chave! A taxa de aprendizado (α) não pode ser muito alta, senão o agente esquece o que aprendeu. Se for muito baixa, demora demais. O fator de desconto (γ) define o quanto o futuro importa. Se for perto de 1, ele pensa mais a longo prazo. Comece com valores usuais (tipo α=0.1, γ=0.9) e vá testando. É pura experimentação para o seu problema específico.
- Exploração vs. Explotação (Epsilon-Greedy): Você precisa achar um equilíbrio. Explorar significa tentar ações novas, mesmo que não pareçam as melhores no momento. Explotação é usar o que você já sabe que funciona. Uma técnica comum é a Epsilon-Greedy: com uma chance ε (epsilon), você explora; senão, explora o que acha que é melhor. Vá diminuindo o ε com o tempo, para o agente ser mais confiante nas boas decisões.
- Tamanho da Tabela Q: Se o seu ambiente for muito grande, a tabela Q pode ficar gigantesca e impraticável (memória e tempo). Nesses casos, procure por variações que usam redes neurais para aproximar os Q-values (Deep Q-Networks – DQN). Mas para começar, a tabela é o caminho.
- Recompensas Claras: Defina as recompensas de forma inteligente. Uma recompensa pequena e frequente pode guiar melhor o agente do que uma recompensa gigante só no final. Pense no que você quer que ele aprenda e como pode incentivar esse comportamento.
Perguntas Frequentes sobre Q-Learning
Eu sei que podem surgir dúvidas, então vamos esclarecer algumas coisas:
- 1. O Q-Learning funciona para qualquer problema?
- Quase! Ele é ótimo para problemas com estados e ações discretos. Se o seu ambiente tem muitas variáveis contínuas ou um espaço de estados infinito, pode ser que ele não seja a ferramenta mais eficiente sem adaptações ou o uso de técnicas como DQN.
- 2. O que acontece se as recompensas forem negativas?
- Tranquilo! O algoritmo lida bem com recompensas negativas. Na verdade, ele pode aprender a evitar situações que levam a grandes penalidades, o que é exatamente o objetivo em muitos cenários.
- 3. Quando devo parar de treinar o agente?
- Geralmente, você monitora a performance. Se a performance estabilizar (o agente parar de melhorar significativamente suas decisões) ou atingir um nível aceitável, você pode considerar o treinamento encerrado. Ou, se o tempo/custo de treinamento se tornar proibitivo.
- 4. A Tabela Q é a única forma de armazenar os Q-values?
- Não. Como mencionei nas dicas, para problemas complexos, redes neurais são usadas para aproximar a função Q. Mas para começar e entender o conceito, a tabela é a abordagem mais didática e direta.
Conclusão: Q-Learning na Prática
Pois é, o Q-Learning é uma ferramenta poderosa e, na minha experiência, uma porta de entrada fantástica para o mundo do Reinforcement Learning. Ele te ensina sobre tomada de decisão sequencial de um jeito muito intuitivo: aprende com os erros e recompensa os acertos.
Vamos combinar: não é mágica, exige um bom entendimento do seu problema, ajuste nos parâmetros e paciência. Mas quando você vê o agente aprendendo a navegar em um labirinto, otimizando uma rota ou tomando a melhor decisão em um jogo, a sensação é de realização total.
Se você está pensando em automatizar decisões complexas ou criar sistemas que aprendem com a experiência, o Q-Learning é um ponto de partida sólido. Explore, experimente e, com certeza, você vai otimizar suas próprias ‘decisões’ no mundo da tecnologia!