

O volume de dados em 2026 é colossal. Empresas se afogam em informações sem saber o que fazer. O data lake surge como a revolução na gestão desses dados, um repositório centralizado que promete flexibilidade e escalabilidade para ir além da análise superficial. Este artigo vai te guiar pelo universo do data lake, mostrando como ele está transformando negócios e o que você precisa saber para se destacar.
O que é um Data Lake e por que ele é essencial em 2026?
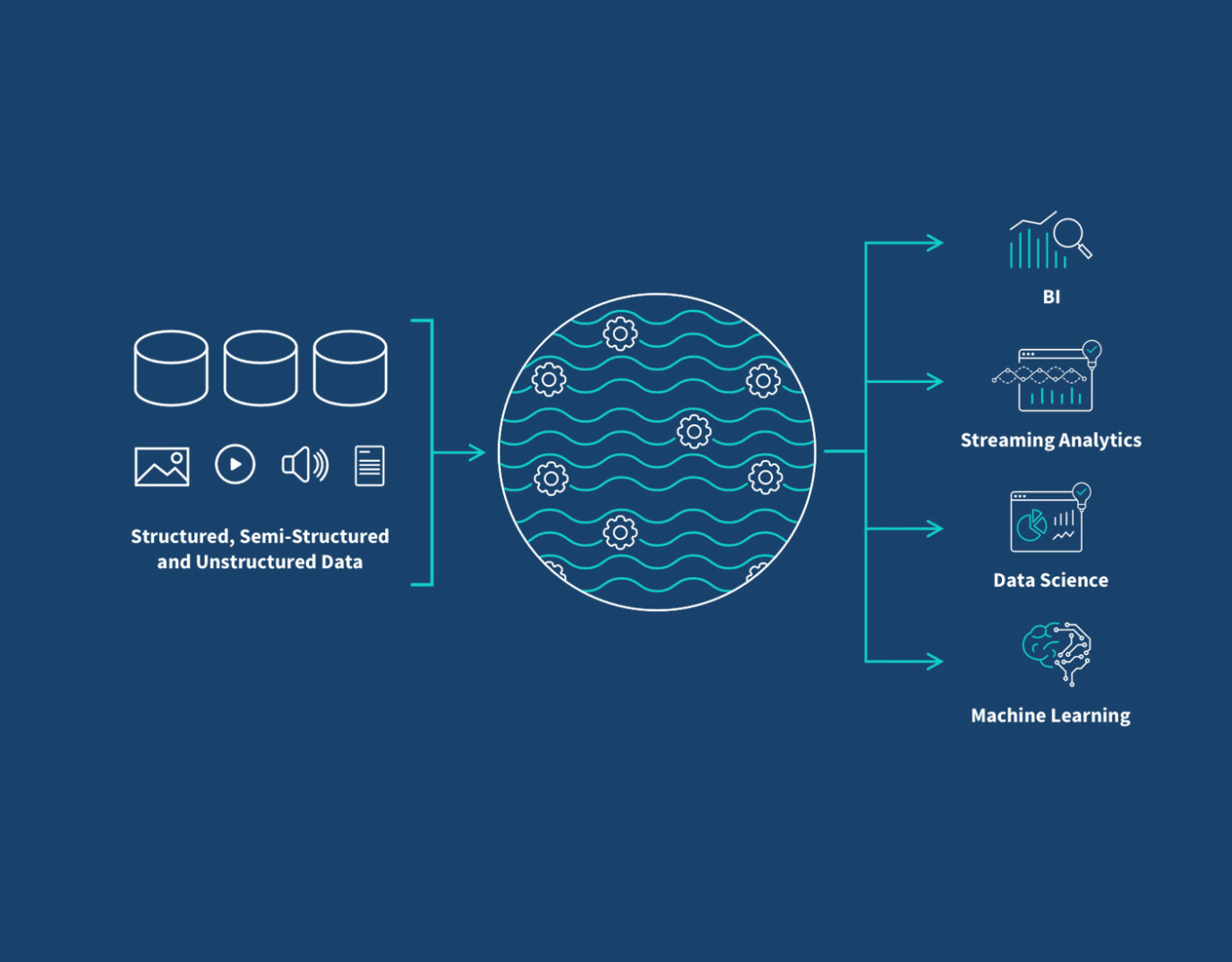
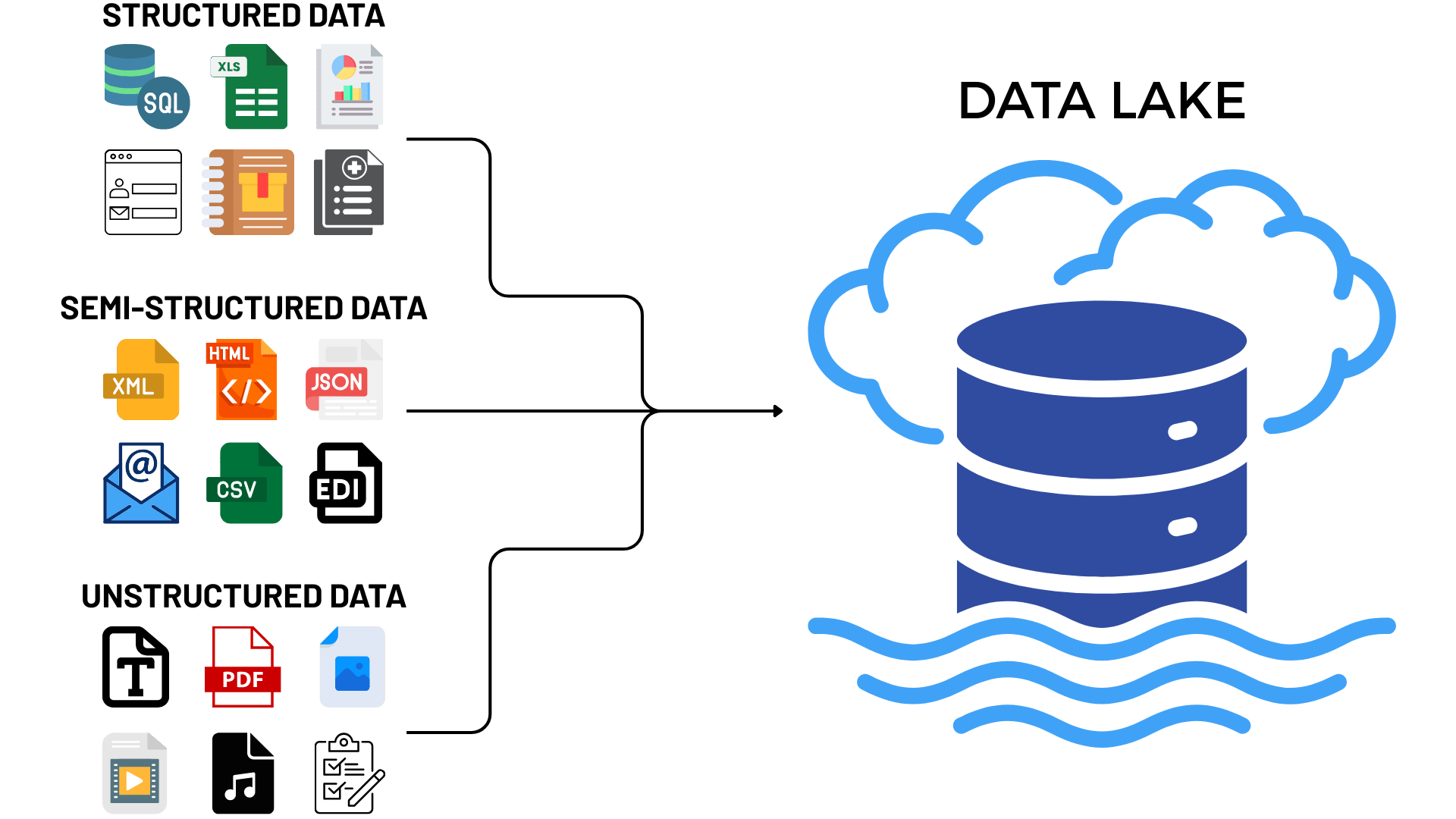
Um data lake é, em essência, um grande lago digital. Ele guarda dados brutos, em seu formato original, sem a necessidade de estruturação prévia. Isso significa que você pode jogar tudo lá dentro: textos, imagens, áudios, vídeos, dados de sensores, logs de sistemas. A flexibilidade é o grande trunfo.
Diferente dos antigos bancos de dados ou data warehouses, que exigiam que você definisse a estrutura dos dados antes de armazená-los (o famoso ‘schema-on-write’), o data lake adota o ‘schema-on-read’. Você só define como vai ler e usar os dados quando realmente precisar.
Pois é, essa abordagem libera o potencial analítico dos seus dados. Você não perde nenhuma informação valiosa por não ter previsto sua utilidade no momento do armazenamento. Dá para analisar dados de formas que você nem imaginava serem possíveis antes.
“Um Data Lake é um repositório centralizado para dados brutos (estruturados, semiestruturados ou não estruturados) que opera com ‘schema-on-read’, permitindo flexibilidade e escalabilidade. Sua evolução natural é o Data Lakehouse, que combina a flexibilidade do Lake com a performance e transações ACID do Data Warehouse.”
Data Lake em 2026: A Revolução na Gestão de Dados que Você Precisa Conhecer
Em 2026, a forma como as empresas lidam com seus dados passou por uma transformação sísmica, e o Data Lake está no centro dessa revolução. Pense nele como um vasto oceano digital onde todos os tipos de dados podem ser armazenados em seu formato original, brutos e sem a rigidez de estruturas pré-definidas. Essa flexibilidade permite que organizações retenham informações valiosas que, de outra forma, poderiam ser descartadas por não se encaixarem em modelos tradicionais.
O principal objetivo de um Data Lake é democratizar o acesso aos dados, permitindo que cientistas de dados, analistas e outros profissionais explorem e descubram insights de maneira ágil. Ao contrário dos sistemas mais antigos, que exigiam processamento e modelagem antes do armazenamento, o Data Lake adota uma abordagem de ‘schema-on-read’, onde a estrutura é aplicada no momento da consulta. Isso agiliza a ingestão e abre um leque de possibilidades analíticas.
| Característica | Descrição |
| Armazenamento | Repositório centralizado para dados brutos e processados. |
| Flexibilidade | Aceita dados estruturados, semiestruturados e não estruturados. |
| Escalabilidade | Projetado para crescer conforme o volume de dados aumenta, especialmente em nuvem. |
| Custo | Geralmente mais econômico para armazenamento em larga escala. |
| Uso | Análise exploratória, machine learning, big data analytics. |
| Abordagem | Schema-on-read (estrutura definida na leitura). |
O que é um Data Lake?
Um Data Lake é, em sua essência, um repositório centralizado que permite armazenar grandes volumes de dados brutos em seu formato nativo. A beleza está na sua capacidade de aceitar qualquer tipo de dado: de bancos de dados relacionais (como transações de vendas), a logs de servidores, arquivos de mídia social, imagens, vídeos e dados de sensores IoT. Essa diversidade é crucial para a análise moderna, pois muitos insights valiosos residem em dados não tradicionais.
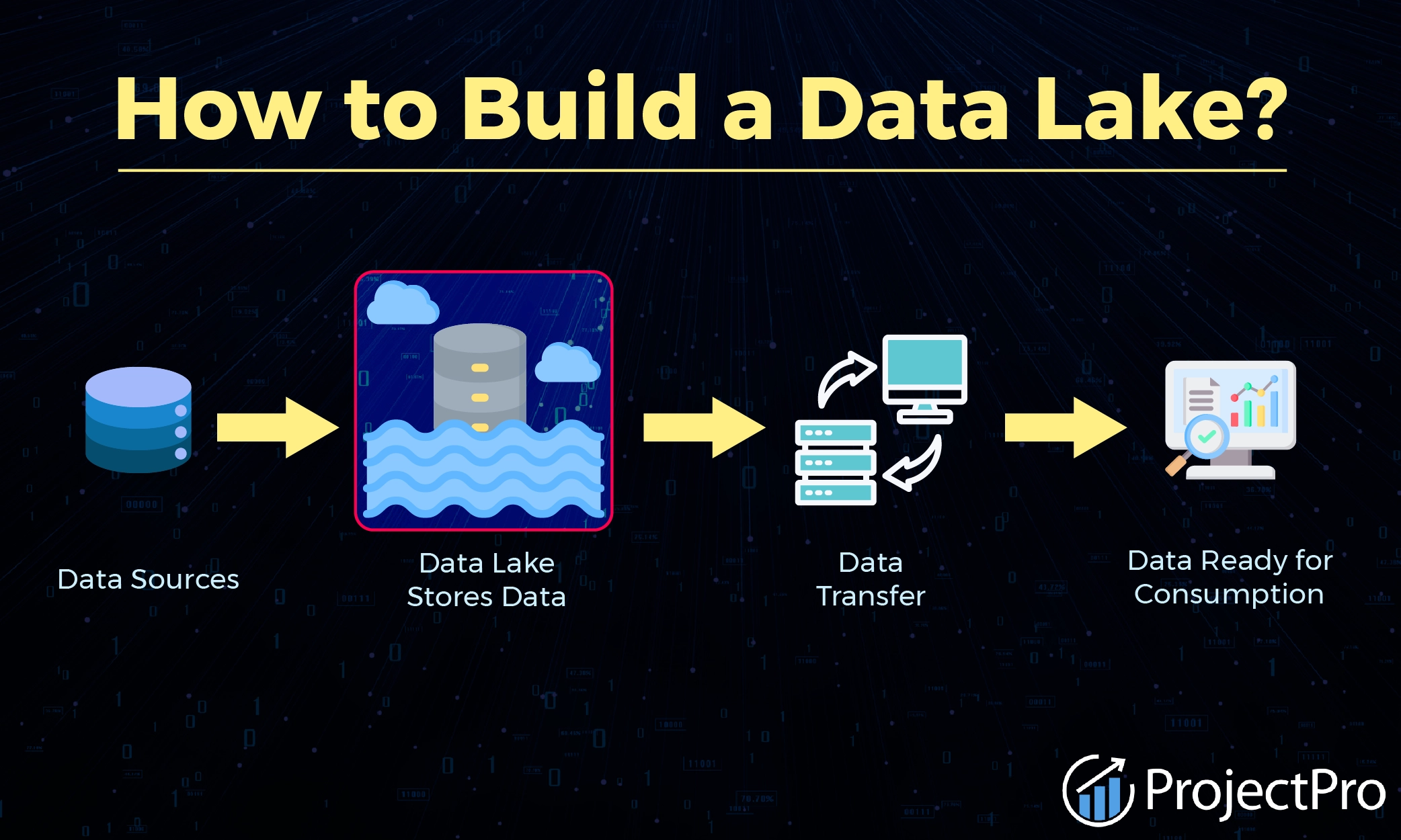
A ideia central é não descartar dados por não saber como usá-los no momento. Ao armazenar tudo em um local acessível e escalável, as empresas se preparam para o futuro, permitindo que equipes de análise e ciência de dados explorem esses dados conforme novas perguntas surgem ou novas tecnologias analíticas se tornam disponíveis. É um investimento em potencial futuro.
Principais Características do Data Lake
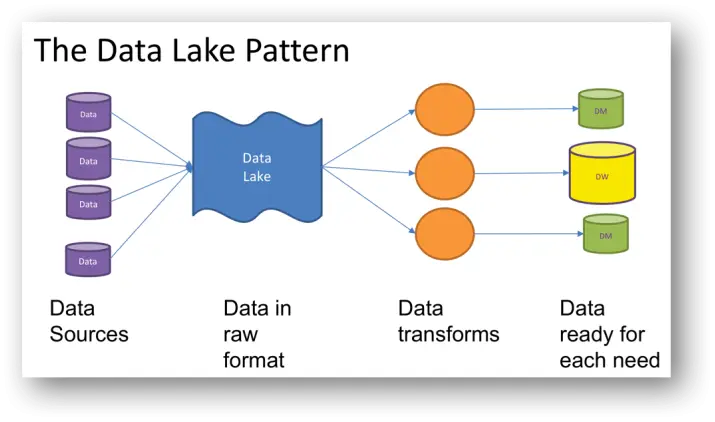
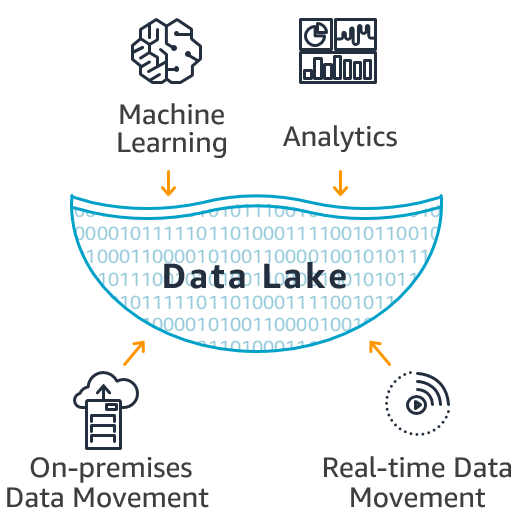
A arquitetura de um Data Lake é pensada para máxima flexibilidade e escalabilidade. Uma das suas características mais marcantes é a capacidade de ingerir dados em seu formato bruto, sem a necessidade de um esquema pré-definido. Isso contrasta diretamente com os modelos tradicionais de banco de dados. Além disso, a infraestrutura de armazenamento de objetos em nuvem, como Amazon S3 ou Azure Blob Storage, é fundamental, oferecendo custos baixos e elasticidade para lidar com volumes massivos de informação.
A capacidade de processamento em paralelo e a integração com diversas ferramentas analíticas e de machine learning também são diferenciais. Isso permite que os dados sejam transformados e analisados de acordo com a necessidade específica de cada projeto, liberando o potencial analítico de forma dinâmica. A governança, embora desafiadora, é um pilar para garantir a usabilidade e segurança dos dados armazenados.
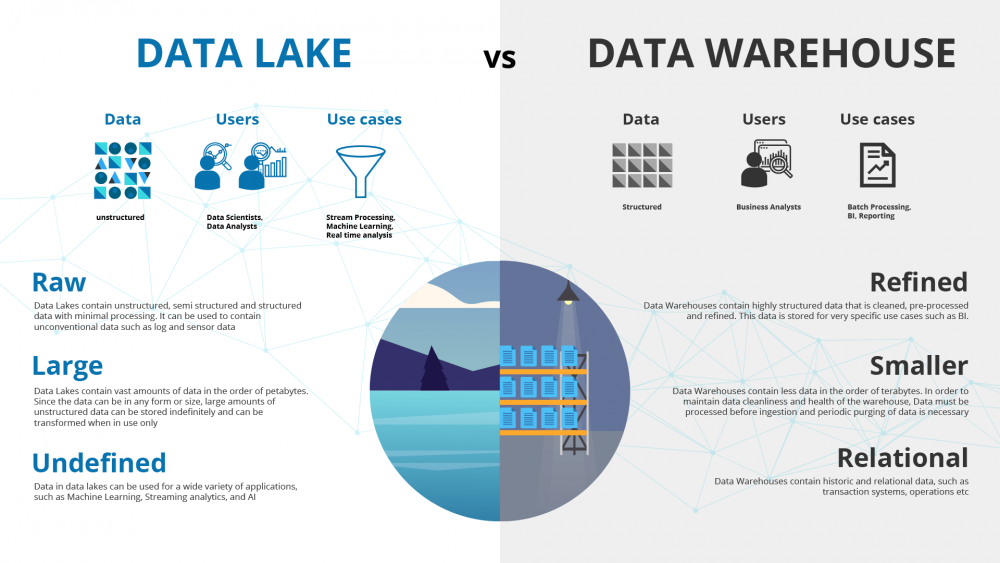
Data Lake vs. Data Warehouse: Entenda as Diferenças
A distinção entre um Data Lake e um Data Warehouse é fundamental para entender a evolução da gestão de dados. O Data Warehouse, por décadas, foi o padrão ouro para análise de negócios. Ele armazena dados já processados, limpos e estruturados, otimizados para consultas rápidas e relatórios específicos. Sua abordagem é ‘schema-on-write’, onde a estrutura é definida antes que os dados sejam carregados.
Já o Data Lake opera com ‘schema-on-read’. Ele armazena dados brutos, permitindo maior flexibilidade e um custo de armazenamento geralmente menor. Enquanto o Data Warehouse é ideal para análises preditivas e relatórios padronizados, o Data Lake brilha em exploração de dados, descoberta de novos padrões e em cenários de machine learning que se beneficiam de dados em seu estado mais puro. A escolha entre um ou outro, ou uma combinação, depende do caso de uso específico.
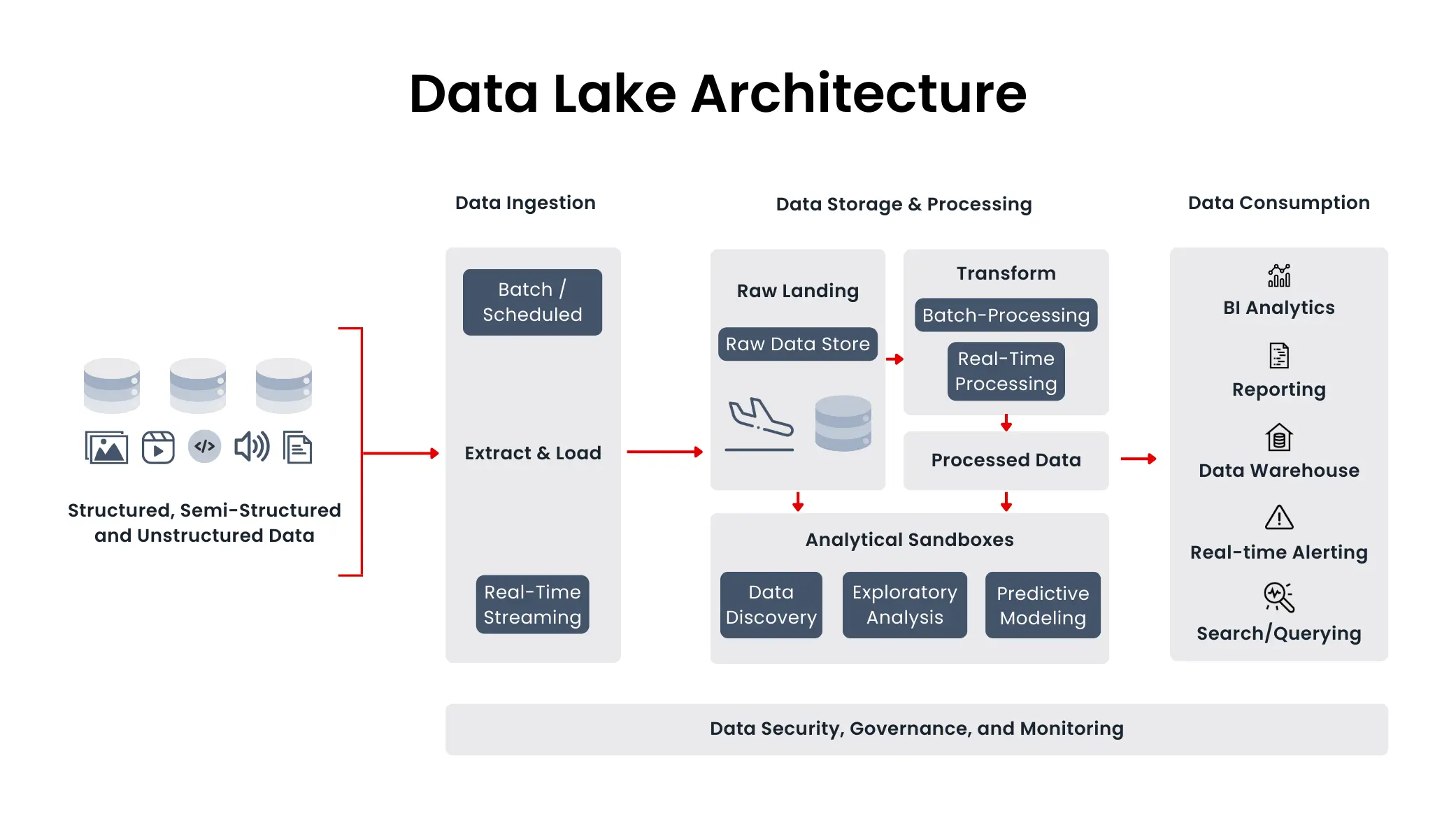
O Perigo do ‘Pântano de Dados’ (Data Swamp) e Como Evitá-lo
Um dos maiores desafios ao implementar um Data Lake é o risco de se transformar em um ‘pântano de dados’ (data swamp). Isso ocorre quando o volume de dados cresce descontroladamente sem qualquer forma de organização, catalogação ou governança. Dados ficam inacessíveis, de baixa qualidade ou irrelevantes, tornando a extração de valor uma tarefa quase impossível.
Para evitar esse cenário, é crucial implementar ferramentas de governança de dados robustas desde o início. Isso inclui a catalogação de metadados, o controle de acesso, a linhagem de dados e a definição de políticas de qualidade. Soluções como AWS Lake Formation e a própria estrutura do Azure Data Lake Storage oferecem mecanismos para gerenciar e proteger seus ativos de dados, garantindo que o lago permaneça um recurso valioso e não um depósito caótico.
Evolução para o Data Lakehouse
O cenário de dados em 2026 não se resume apenas ao Data Lake puro. A evolução natural nos levou ao conceito de Data Lakehouse. Essa arquitetura híbrida busca unir o melhor dos dois mundos: a flexibilidade e o baixo custo de armazenamento do Data Lake com a estrutura, a performance e as garantias transacionais (ACID) dos Data Warehouses tradicionais. O objetivo é simplificar a arquitetura de dados, reduzindo a necessidade de manter sistemas separados.
O Data Lakehouse permite que dados brutos e processados coexistam em um único repositório, com camadas de metadados e ferramentas que garantem a qualidade e a confiabilidade dos dados. Isso significa que você pode realizar análises complexas de machine learning diretamente sobre os dados que também são usados para relatórios de negócios, sem a complexidade de mover e transformar dados entre sistemas distintos. É a convergência que o mercado pedia.

Plataformas Líderes em Data Lakehouse
O mercado de Data Lakehouse amadureceu significativamente, e algumas plataformas se destacam em 2026. A plataforma Databricks é um dos nomes fortes, oferecendo uma solução unificada para engenharia de dados, ciência de dados e machine learning, construída sobre o conceito de Lakehouse. Eles inovaram ao trazer tabelas Delta Lake, que adicionam confiabilidade e performance aos Data Lakes.
Outra gigante no espaço é a plataforma Snowflake. Embora tenha começado com um foco mais próximo do Data Warehouse em nuvem, a Snowflake evoluiu para suportar cargas de trabalho de Data Lake e Lakehouse de forma nativa, permitindo o armazenamento e a análise de dados não estruturados e semiestruturados com grande eficiência. Ambas as plataformas oferecem escalabilidade, segurança e um ecossistema robusto para diversas necessidades analíticas.
Ferramentas Essenciais para Governança e Segurança em Data Lakes
A governança e a segurança são pilares indispensáveis para o sucesso de qualquer Data Lake. Sem elas, o risco de se deparar com um ‘pântano de dados’ ou sofrer com violações de segurança é altíssimo. Ferramentas de catálogo de dados, como o AWS Glue Data Catalog ou soluções de terceiros, são essenciais para entender o que existe no seu lago, quem é o dono dos dados e qual a sua qualidade. Isso facilita a descoberta e o uso responsável das informações.
Além do catálogo, o controle de acesso granular é fundamental. Mecanismos de autenticação e autorização garantem que apenas usuários autorizados possam acessar dados sensíveis. Soluções como AWS Lake Formation e Azure Data Lake Storage oferecem recursos integrados para gerenciar permissões de forma eficiente, protegendo seus ativos de dados contra acessos indevidos e assegurando a conformidade com regulamentações, como a LGPD.
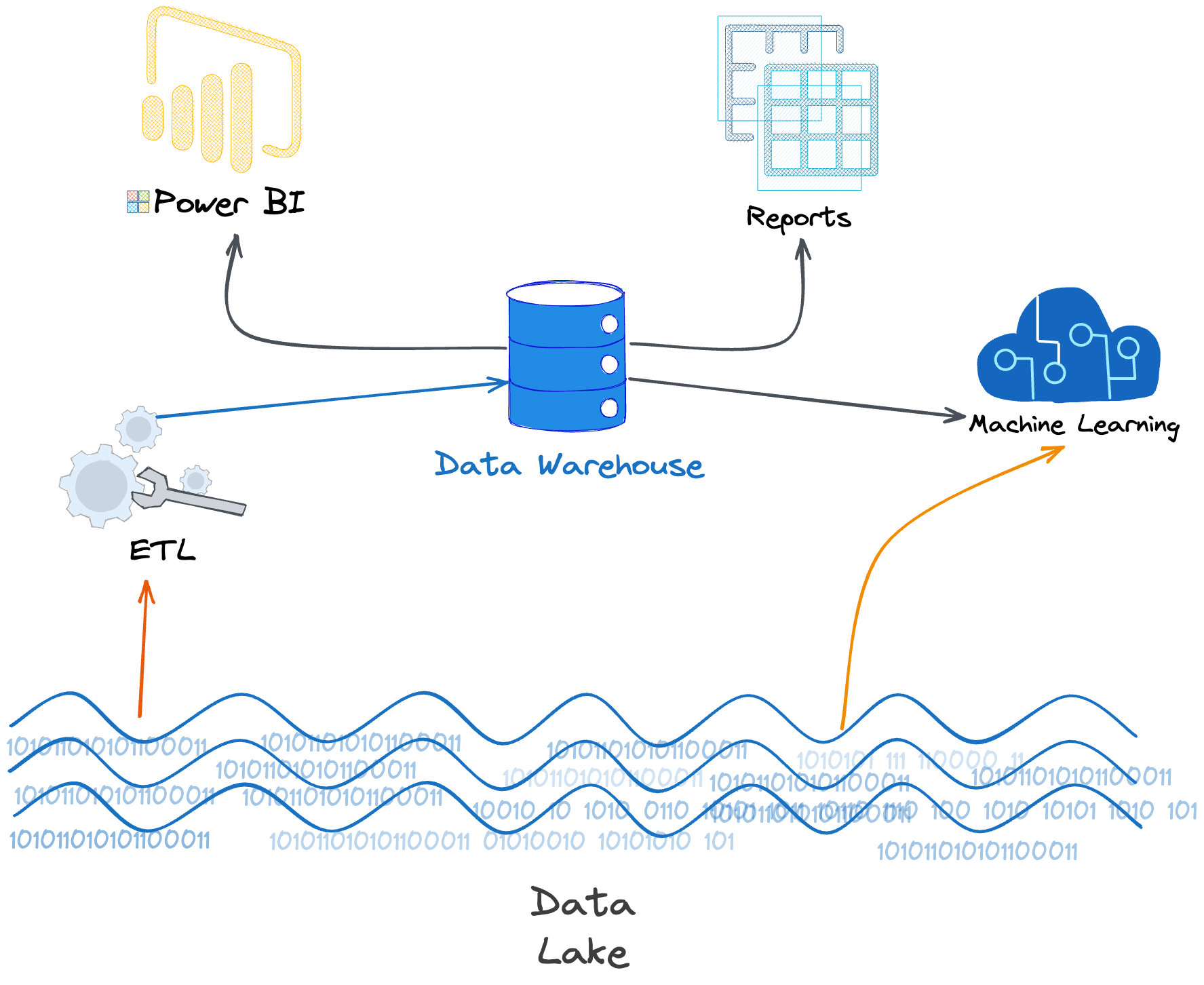
Camadas de Processamento em Arquiteturas de Data Lake (Bronze, Prata, Ouro)
Uma prática recomendada em arquiteturas de Data Lake modernas é a organização em camadas, frequentemente chamadas de Bronze, Prata e Ouro. Essa segmentação ajuda a gerenciar a qualidade e o processamento dos dados de forma estruturada. A camada Bronze recebe os dados brutos, exatamente como foram ingeridos, servindo como um backup imutável. É o ponto de partida para todas as análises.
A camada Prata contém os dados que passaram por um processo de limpeza, validação e enriquecimento inicial. Aqui, dados duplicados são removidos, formatos são padronizados e informações de diferentes fontes podem ser unidas. Finalmente, a camada Ouro abriga os dados prontos para consumo por usuários de negócio, analistas e cientistas de dados. Estes dados são agregados, otimizados para performance e modelados para casos de uso específicos, como dashboards e relatórios de BI, ou para alimentar modelos de machine learning.
Data Lake em 2026: O Veredito Final
A adoção de um Data Lake, ou mais comumente, de uma arquitetura Data Lakehouse, não é mais uma questão de ‘se’, mas de ‘como’. Em 2026, empresas que não possuem uma estratégia clara para gerenciar grandes volumes de dados em um ambiente flexível e escalável estão em desvantagem competitiva. A capacidade de extrair insights de dados brutos, combinada com a performance e a confiabilidade das novas arquiteturas, é um diferencial crucial.
O investimento em um Data Lake ou Lakehouse, quando bem planejado e governado, se traduz em agilidade, inovação e uma tomada de decisão mais informada. Os custos de armazenamento em nuvem tornam essa abordagem acessível até para organizações menores, enquanto plataformas líderes garantem a escalabilidade e a segurança necessárias para os desafios mais complexos. É a base para a inteligência de negócios e a inteligência artificial do futuro.
Dicas Extras
- Fique atento à segurança: Implemente controles de acesso rigorosos e criptografia para proteger seus dados.
- Comece pequeno, pense grande: Inicie com um projeto piloto e escale conforme a necessidade, garantindo que a arquitetura suporte o crescimento.
- Invista em catalogação: Um catálogo de dados bem estruturado é seu melhor amigo para evitar o temido ‘data swamp’.
- Monitore o desempenho: Acompanhe o uso e os custos de armazenamento e processamento para otimizar recursos.
Dúvidas Frequentes
O que é um Data Lake e como ele funciona na prática?
Um Data Lake é um repositório centralizado que armazena grandes volumes de dados brutos, estruturados e não estruturados. Ele funciona com a filosofia de ‘schema-on-read’, o que significa que a estrutura dos dados é definida no momento da consulta, oferecendo grande flexibilidade.
Qual a principal diferença entre Data Lake e Data Warehouse?
A diferença crucial está em como os dados são tratados. O Data Warehouse processa e estrutura os dados antes de armazená-los (‘schema-on-write’), ideal para análises específicas. Já o Data Lake guarda os dados brutos, permitindo análises mais exploratórias e variadas com ‘schema-on-read’.
Como posso evitar que meu Data Lake se torne um ‘Data Swamp’?
Para evitar o ‘data swamp’, é fundamental investir em governança de dados. Isso inclui catalogação, linhagem de dados, políticas de qualidade e segurança. Ferramentas de catálogo e governança são essenciais para manter a organização e a usabilidade do seu data lake.
Conclusão
O Data Lake representa um avanço significativo na gestão de dados, oferecendo escalabilidade e flexibilidade sem precedentes. Ao entender profundamente o que é data lake e como funciona, sua empresa se posiciona na vanguarda da inovação. Para 2026, a tendência é a consolidação do conceito de Data Lakehouse, que une o melhor dos mundos do Data Lake e do Data Warehouse. Explore também a importância de implementar camadas Bronze, Prata e Ouro em um Data Lake para otimizar seus dados.


