

Você se pergunta o que é a clusterização de dados? Em 2026, com o volume colossal de informações que geramos, identificar padrões se tornou um desafio e tanto. Empresas lutam para entender seus clientes e otimizar operações. Mas e se eu te dissesse que existe uma forma inteligente de organizar tudo isso, revelando insights valiosos? Neste post, vamos desvendar o poder da clusterização para transformar seus dados brutos em inteligência acionável.
Como a Clusterização de Dados Organiza Informações Complexas para Você em 2026?
A clusterização é uma técnica poderosa de aprendizado de máquina não supervisionado. Ela trabalha agrupando seus dados em ‘clusters’ ou grupos. Cada grupo contém itens que são semelhantes entre si. Isso te ajuda a ver o que antes era invisível.
Pense nisso como organizar uma caixa cheia de objetos. A clusterização te ajuda a separar itens parecidos, facilitando a compreensão do todo.
Essa organização é crucial para tomar decisões mais assertivas. Você consegue segmentar seu público, detectar anomalias e até otimizar sistemas complexos.
“A clusterização de dados é uma técnica de aprendizado de máquina não supervisionado que organiza automaticamente um conjunto de dados em grupos chamados clusters, garantindo que itens dentro do mesmo grupo sejam altamente similares entre si.”
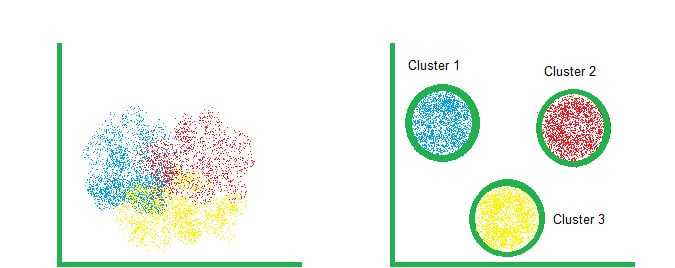
O que é Clusterização de Dados e Para Que Serve em 2026?
Em 2026, a capacidade de extrair significado de volumes massivos de dados é um diferencial competitivo crucial. A clusterização de dados surge como uma técnica de aprendizado de máquina não supervisionado, fundamental para organizar e entender essas informações. Ela funciona agrupando pontos de dados semelhantes em conjuntos coesos, chamados clusters. Isso permite identificar padrões ocultos e estruturas intrínsecas nos seus dados, sem a necessidade de rótulos prévios.
Pense na clusterização como uma forma inteligente de segmentar e categorizar. Ao invés de você ter que dizer para o algoritmo o que cada dado representa, ele próprio descobre as semelhanças e as agrupa. Essa abordagem é poderosa porque revela insights que poderiam passar despercebidos em análises superficiais, abrindo portas para decisões mais assertivas e estratégias mais eficazes.
| Característica | Descrição |
| Tipo de Aprendizado | Não Supervisionado |
| Objetivo Principal | Agrupar dados semelhantes em clusters |
| Métrica de Similaridade Comum | Distância Euclidiana |
| Algoritmos Populares | K-Means, DBSCAN, Hierárquico |
| Aplicações Chave | Segmentação de clientes, sistemas de recomendação, detecção de anomalias |
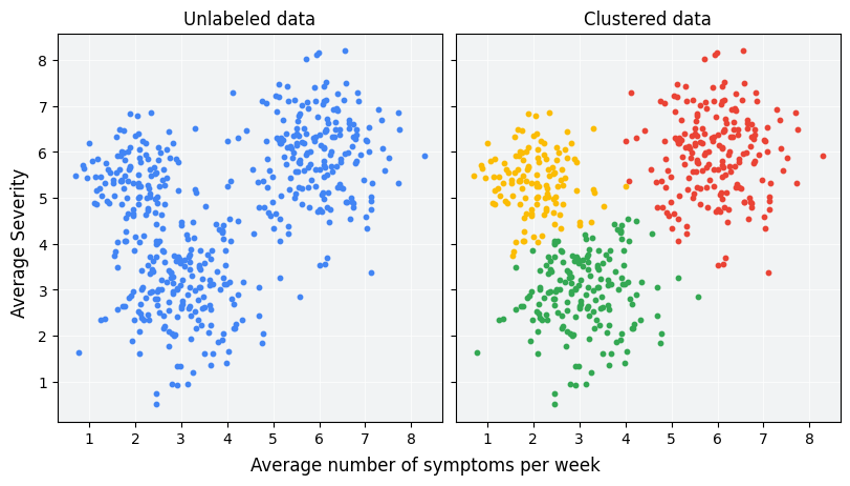
O que é Clusterização de Dados?
A clusterização de dados é, em essência, um processo de descoberta de grupos. O objetivo é particionar um conjunto de observações em subconjuntos, de forma que os dados dentro de cada subconjunto sejam o mais semelhantes possível entre si, e o mais diferentes possível dos dados em outros subconjuntos. É uma ferramenta valiosa para explorar dados não rotulados, revelando a estrutura natural que eles contêm.
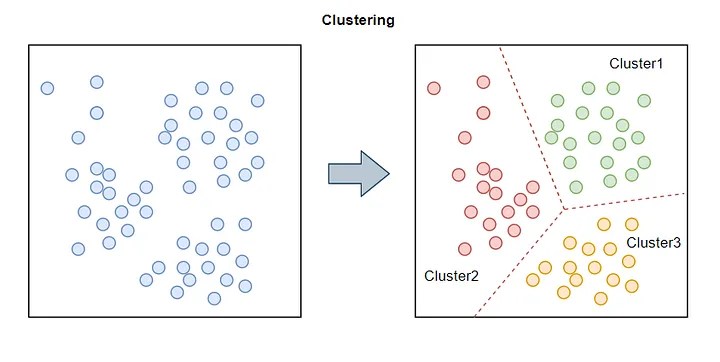
Principais Características da Clusterização
A beleza da clusterização reside em sua flexibilidade e na capacidade de revelar estruturas latentes. Ela opera sem supervisão, o que significa que não há um ‘gabarito’ para o algoritmo seguir; ele aprende as relações por conta própria. Isso a torna ideal para tarefas exploratórias, onde o objetivo é entender a composição dos dados antes de aplicar modelos mais complexos.
A clusterização não supervisionada é a arte de encontrar ordem no caos, permitindo que os dados falem por si mesmos.

Baseada em Similaridade: A Distância Euclidiana
Para que a clusterização funcione, é preciso definir como medir a ‘semelhança’ ou ‘proximidade’ entre os pontos de dados. A métrica mais utilizada para isso é a Distância Euclidiana. Ela calcula a distância em linha reta entre dois pontos em um espaço multidimensional. Quanto menor a distância, mais semelhantes são os pontos, e maior a probabilidade de pertencerem ao mesmo cluster.
A escolha da métrica de similaridade é crucial e pode impactar diretamente os resultados. Além da Euclidiana, outras métricas como a Distância de Manhattan ou a similaridade de cosseno podem ser mais adequadas dependendo da natureza dos seus dados e do problema que você está tentando resolver.
Exemplos de Aplicação da Clusterização
As aplicações de clusterização são vastas e impactam diversas áreas do negócio e da tecnologia. Desde a organização de informações até a personalização de experiências, a clusterização se mostra uma ferramenta versátil. Ela permite descobrir grupos naturais nos dados, facilitando a compreensão de comportamentos e a identificação de tendências.
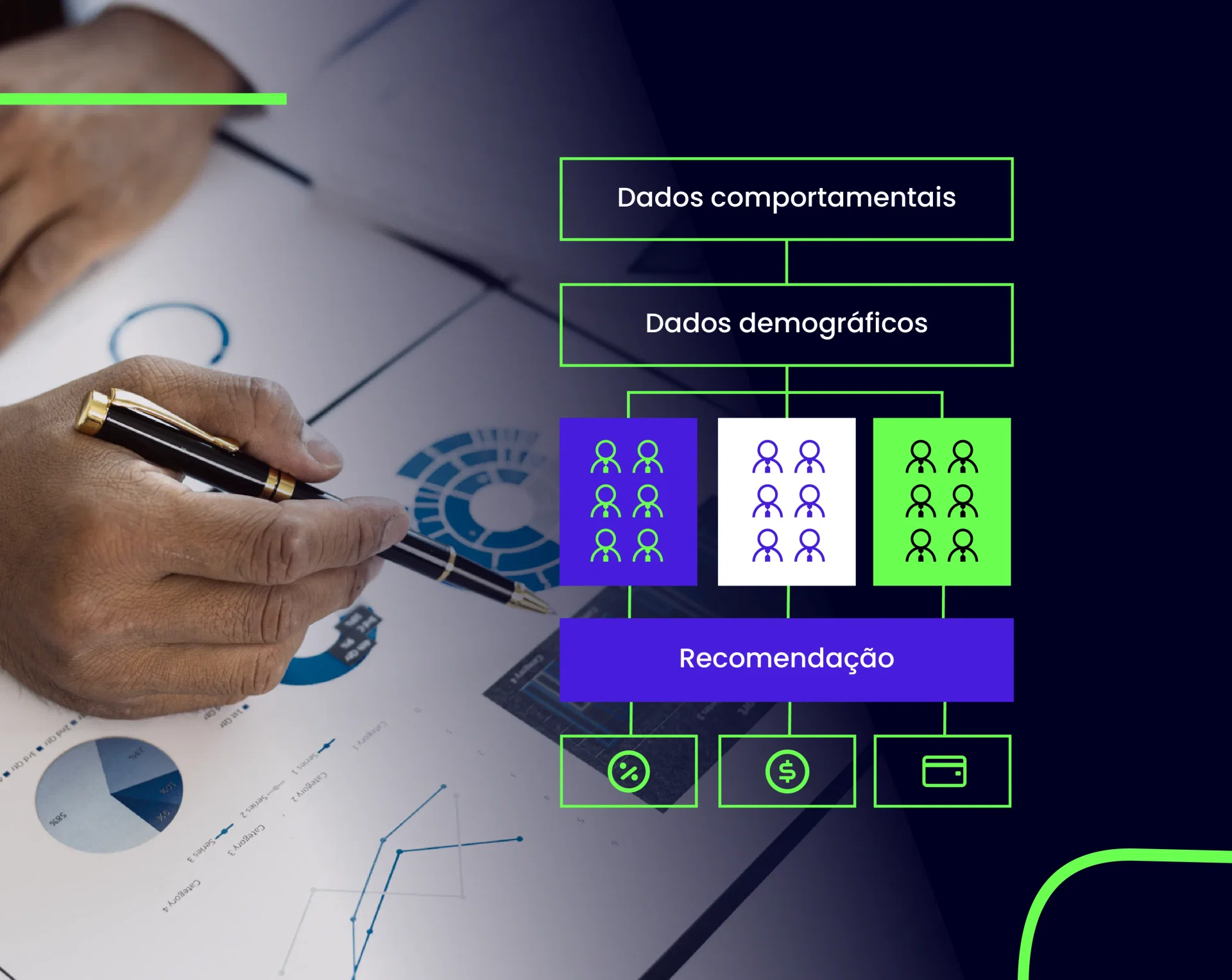
Clusterização no Marketing e Sistemas de Recomendação
No marketing, a clusterização é uma aliada poderosa para a segmentação de clientes. Ao agrupar clientes com comportamentos de compra, demografia ou interesses similares, as empresas podem criar campanhas de marketing mais direcionadas e personalizadas. Isso aumenta a eficácia das ações e otimiza o retorno sobre o investimento.
Em sistemas de recomendação, como os utilizados por plataformas de streaming e e-commerce, a clusterização ajuda a identificar usuários com gostos parecidos. Com base nesses grupos, é possível sugerir produtos, filmes ou músicas que provavelmente agradarão a um determinado usuário, melhorando a experiência e o engajamento. Exemplos clássicos incluem as recomendações personalizadas da Spotify e da Netflix.
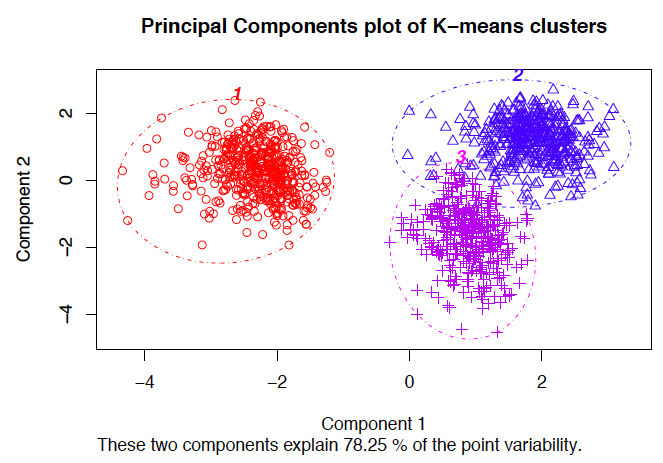
Algoritmos Comuns de Clusterização
Existem diversos algoritmos para realizar a clusterização, cada um com suas particularidades e adequados para diferentes cenários. A escolha do algoritmo certo depende da estrutura dos seus dados, do número de clusters desejado e da performance esperada.
K-Means: Divisão em Grupos Fixos
O algoritmo K-Means é um dos mais populares devido à sua simplicidade e eficiência. Ele funciona dividindo os dados em um número ‘K’ pré-definido de grupos. O algoritmo itera, calculando os centróides (pontos médios) de cada cluster e reatribuindo os pontos de dados ao centróide mais próximo, até que a configuração dos clusters se estabilize.

DBSCAN: Agrupamento por Densidade
Diferente do K-Means, o algoritmo DBSCAN (Density-Based Spatial Clustering of Applications with Noise) agrupa os dados com base na densidade de pontos. Ele identifica regiões densamente povoadas e as agrupa em clusters, sendo particularmente eficaz em detectar ruídos (pontos isolados) e em identificar clusters com formatos irregulares que outros algoritmos poderiam ter dificuldade em capturar.
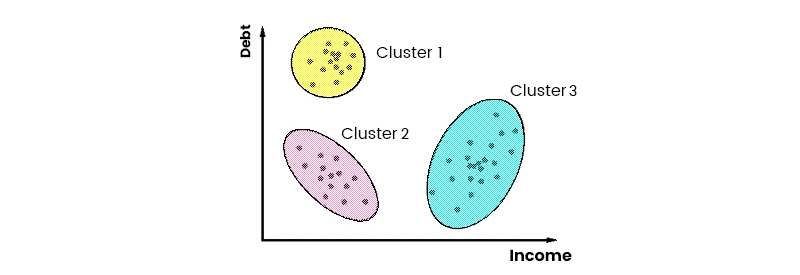
O Impacto da Clusterização em 2026: Resultados e Veredito
Em 2026, a clusterização de dados não é apenas uma técnica, mas uma necessidade estratégica. Ela permite que empresas transformem dados brutos em inteligência acionável, otimizando operações, entendendo melhor seus clientes e identificando novas oportunidades de negócio. Os resultados esperados incluem maior eficiência em campanhas de marketing, personalização aprimorada da experiência do usuário e uma detecção mais robusta de fraudes e anomalias.
O investimento em ferramentas e conhecimento para aplicar clusterização se traduz diretamente em vantagem competitiva. A capacidade de segmentar e compreender seus dados de forma profunda e automatizada é o que separa as empresas que apenas coletam dados daquelas que realmente as utilizam para inovar e crescer. Portanto, dominar a clusterização é um passo essencial para qualquer organização que busca prosperar no cenário atual de dados.
Dicas Extras
- Use a Distância Euclidiana com Cautela: Embora seja a métrica mais comum para o K-Means, a Distância Euclidiana pode ser enganosa em dados com muitas dimensões ou escalas diferentes. Considere normalizar seus dados antes de aplicá-la.
- Entenda os Limites do K-Means: O K-Means exige que você defina o número de clusters (‘K’) antecipadamente e é sensível a outliers. Se você não tem certeza sobre o número ideal de clusters, ou se seus dados contêm anomalias, talvez outros algoritmos sejam mais adequados.
- Explore Algoritmos Baseados em Densidade: O DBSCAN é uma alternativa poderosa ao K-Means, especialmente quando os clusters têm formas irregulares ou quando há ruído nos dados. Ele não requer a definição prévia do número de clusters.
- Valide Seus Clusters: Não basta apenas rodar um algoritmo. Use métricas de avaliação de clusterização, como o Silhouette Score, para entender a qualidade dos grupos formados e comparar diferentes abordagens.
- Visualize Seus Dados: Antes e depois da clusterização, a visualização é sua maior aliada. Técnicas como PCA (Principal Component Analysis) podem ajudar a reduzir a dimensionalidade e a visualizar os clusters em 2D ou 3D.
Dúvidas Frequentes
O que é clusterização de dados e como funciona?
A clusterização de dados é uma técnica de aprendizado de máquina não supervisionado. Essencialmente, ela agrupa um conjunto de objetos de forma que objetos no mesmo grupo (chamado de cluster) sejam mais semelhantes entre si do que com aqueles em outros grupos. O funcionamento básico envolve calcular a similaridade ou distância entre os pontos de dados e, com base nisso, formar os clusters. Algoritmos como K-Means e DBSCAN são amplamente utilizados para isso.
Quais são as aplicações da clusterização de dados em machine learning?
As aplicações são vastas! Na segmentação de clientes, por exemplo, empresas usam clusterização para entender diferentes perfis de consumidores e direcionar campanhas de marketing. Sistemas de recomendação, como os da Netflix ou Spotify, utilizam a clusterização para agrupar usuários com gostos similares. Além disso, é fundamental na detecção de anomalias e fraudes, identificando padrões incomuns nos dados.
Qual a diferença entre os algoritmos K-Means e DBSCAN?
O K-Means é um algoritmo popular que divide os dados em um número pré-definido (‘K’) de clusters. Ele funciona bem com clusters de formato esférico e requer que você saiba o número de clusters antecipadamente. Já o DBSCAN agrupa pontos com base na densidade. Ele é excelente para identificar clusters de formatos arbitrários e para lidar com ruído nos dados, sem a necessidade de definir o número de clusters previamente. A escolha entre eles depende muito da natureza dos seus dados e do problema que você quer resolver.
Conclusão: O Futuro é Clusterizado
Chegamos ao fim da nossa jornada pela clusterização de dados. Como você pôde ver, essa técnica de aprendizado de máquina não supervisionado é uma ferramenta poderosa para extrair insights valiosos dos seus dados. Em 2026, a capacidade de agrupar e entender padrões em grandes volumes de informação será ainda mais crucial. Seja para otimizar campanhas de marketing digital ou para aprofundar a análise de dados, a clusterização oferece caminhos práticos. Explore a fundo os algoritmos de clusterização e suas aplicações, pois o conhecimento em como aplicar a clusterização de dados em machine learning abrirá muitas portas para você.


