

Você já se perguntou como os computadores tomam decisões complexas, quase como um especialista humano? O algoritmo random forest é a chave para entender essa magia. Se você busca previsões mais precisas e modelos de machine learning mais robustos, mas se sente perdido em termos técnicos, este post é para você. Vamos desmistificar o algoritmo random forest e mostrar como ele pode ser seu aliado poderoso em 2026.
Como o algoritmo Random Forest toma decisões precisas e confiáveis em projetos de Machine Learning?
O segredo do algoritmo random forest está na sabedoria coletiva.
Ele combina várias árvores de decisão para chegar a um resultado mais forte.
Isso diminui drasticamente as chances de erros isolados de uma única árvore.
O resultado é uma performance superior e maior confiabilidade nas suas previsões.
“O Random Forest é um algoritmo de aprendizado de máquina supervisionado que combina várias árvores de decisão para gerar uma previsão única e mais precisa.”
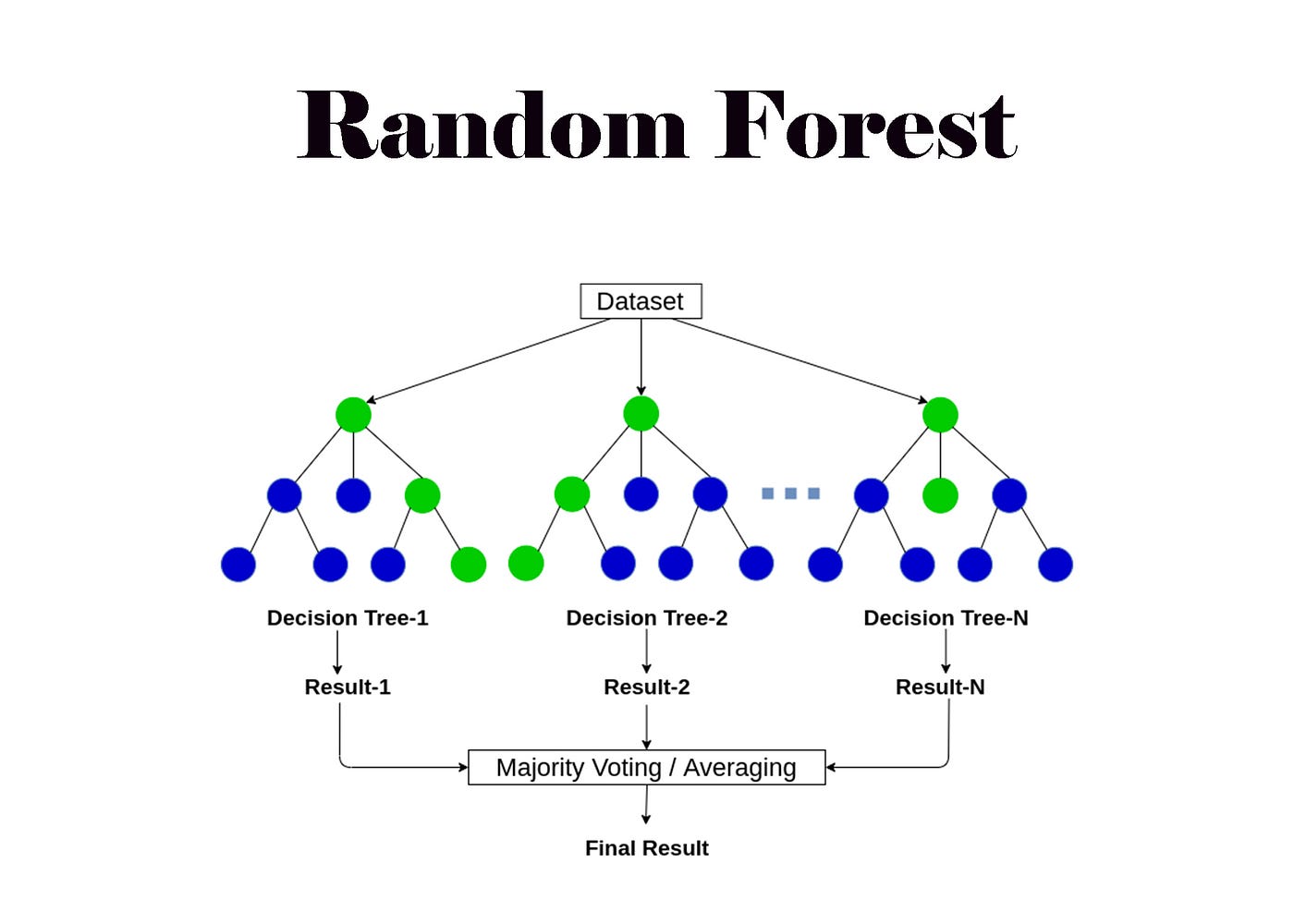
O que é e para que serve o Algoritmo Random Forest?
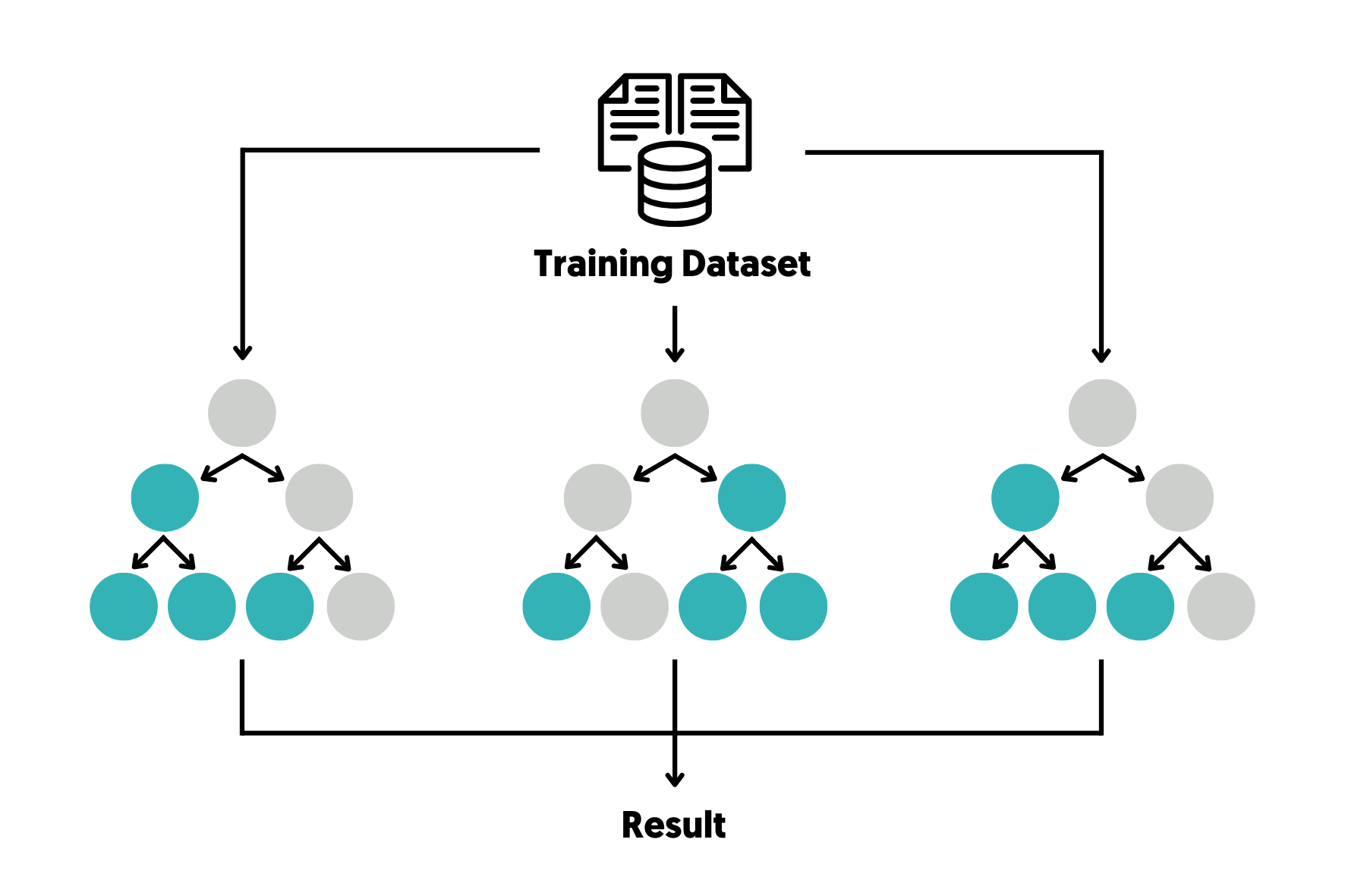
O Random Forest, ou Floresta Aleatória, é um algoritmo de aprendizado de máquina supervisionado que se destaca pela sua robustez e precisão. Ele opera combinando múltiplos modelos de árvore de decisão para chegar a uma previsão mais confiável. Pense nele como um comitê de especialistas, onde cada membro (árvore de decisão) tem uma opinião, e a decisão final é tomada por consenso, o que geralmente leva a um resultado mais acertado do que a opinião de um único especialista.
A principal utilidade do Random Forest reside na sua capacidade de lidar com problemas complexos de classificação e regressão. Ele é particularmente eficaz quando os dados apresentam muitas variáveis ou quando a relação entre elas não é linear. Essa versatilidade o torna uma ferramenta poderosa em diversas áreas, desde a análise financeira até o diagnóstico médico.
Para entender melhor seu funcionamento e características, veja este raio-X:
| Nome | Random Forest (Floresta Aleatória) |
| Tipo | Aprendizado Supervisionado |
| Objetivo | Classificação e Regressão |
| Componente Principal | Árvores de Decisão Múltiplas |
| Mecanismo Chave | Bagging e Seleção Aleatória de Atributos |
| Popularidade | Alta, devido à precisão e robustez |
| Fontes de Referência | IBM, Built In, NVIDIA |
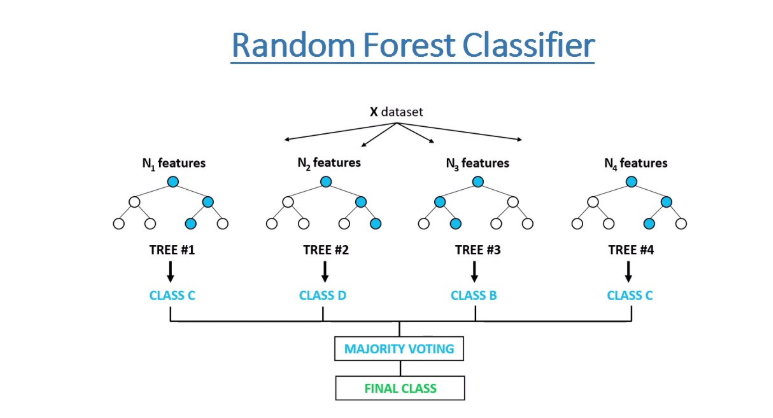
Como funciona o Random Forest
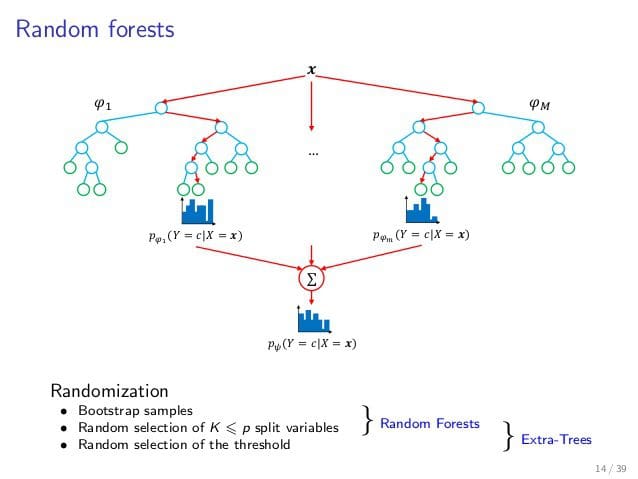
O Random Forest constrói um conjunto de árvores de decisão durante o treinamento. Cada árvore é treinada em uma amostra aleatória dos dados de treinamento (com reposição, técnica conhecida como bagging) e, em cada nó da árvore, apenas um subconjunto aleatório de atributos é considerado para a divisão. Essa dupla camada de aleatoriedade é crucial para o desempenho do algoritmo.
Ao fazer uma previsão, cada árvore na floresta processa a entrada independentemente. Para tarefas de classificação, a classe mais votada entre todas as árvores é o resultado final. Em problemas de regressão, a média das previsões de todas as árvores é utilizada.
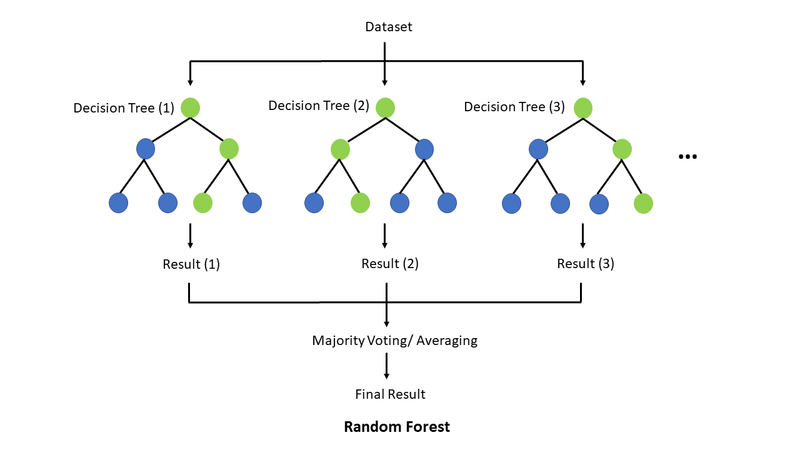
Mecanismos de Aleatoriedade: Bagging e Seleção Aleatória de Atributos
A força do Random Forest reside em dois mecanismos de aleatoriedade que reduzem o sobreajuste (overfitting) e aumentam a generalização. O Bagging (Bootstrap Aggregating) envolve a criação de múltiplas amostras de treinamento a partir dos dados originais, selecionando observações com reposição. Isso garante que cada árvore seja treinada em um conjunto de dados ligeiramente diferente.
Complementarmente, a Seleção Aleatória de Atributos ocorre em cada nó de decisão. Em vez de considerar todos os atributos disponíveis para encontrar a melhor divisão, o algoritmo seleciona aleatoriamente um subconjunto deles. Essa abordagem força as árvores a explorar diferentes características, evitando que uma ou poucas variáveis dominem o processo de decisão e levando a uma floresta mais diversificada e robusta.
A diversidade entre as árvores é a chave para o sucesso de um modelo de ensemble como o Random Forest. Quanto mais diferentes forem as árvores, melhor será a capacidade de generalização do modelo final.
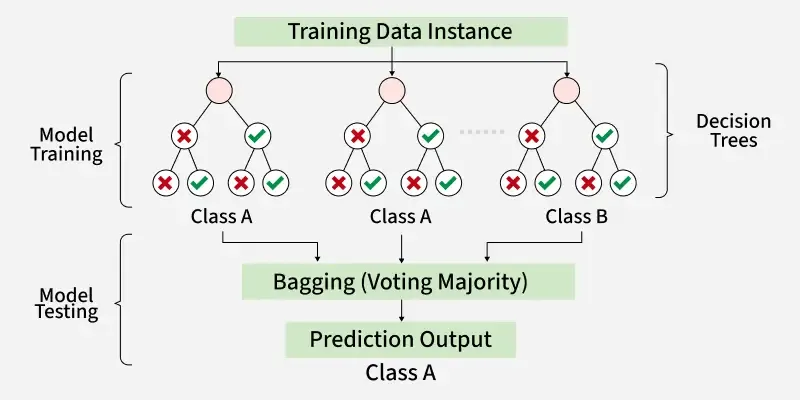
Decisão Final: Classificação e Regressão
No contexto de classificação, o Random Forest funciona agregando os votos de cada árvore de decisão. Se você tem 100 árvores e 70 delas preveem a classe ‘A’ e 30 preveem a classe ‘B’, a previsão final do modelo será ‘A’. Esse método de votação majoritária é simples, mas extremamente eficaz para reduzir erros e vieses individuais das árvores.
Para problemas de regressão, o processo é similar, mas em vez de votos, calcula-se a média das previsões de todas as árvores. Se as árvores preverem valores como 10.5, 11.2, 10.8, a previsão final será a média desses valores, proporcionando uma estimativa contínua e mais estável.
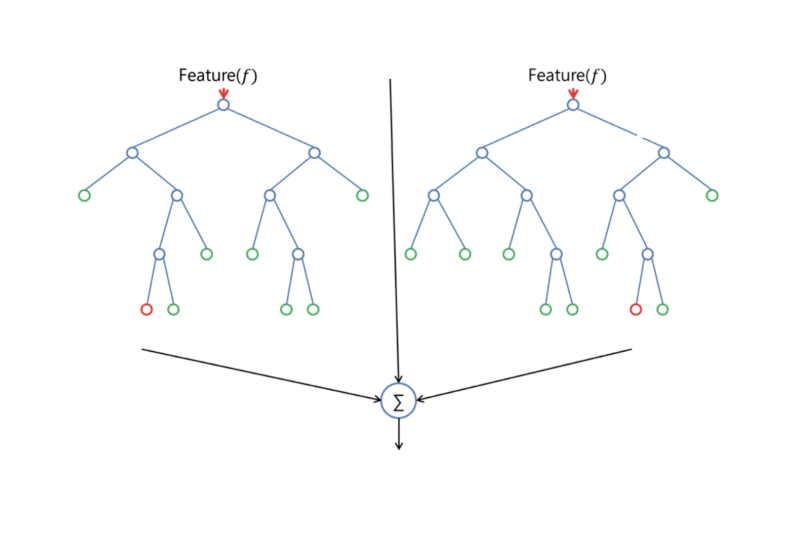
Principais Vantagens do Random Forest
Uma das grandes vantagens do Random Forest é sua alta precisão. Ele frequentemente supera outros algoritmos em diversas tarefas, especialmente quando há interações complexas entre as variáveis. Além disso, o algoritmo é relativamente robusto ao ruído e a dados ausentes, pois o bagging ajuda a mitigar o impacto de observações anômalas.
Outro ponto forte é a sua capacidade de estimar a importância das variáveis. Isso significa que o Random Forest pode nos dizer quais características dos dados foram mais influentes na tomada de decisão, fornecendo insights valiosos para a análise. A sua implementação é também facilitada por bibliotecas populares, como pode ser visto em guias como o da Built In.
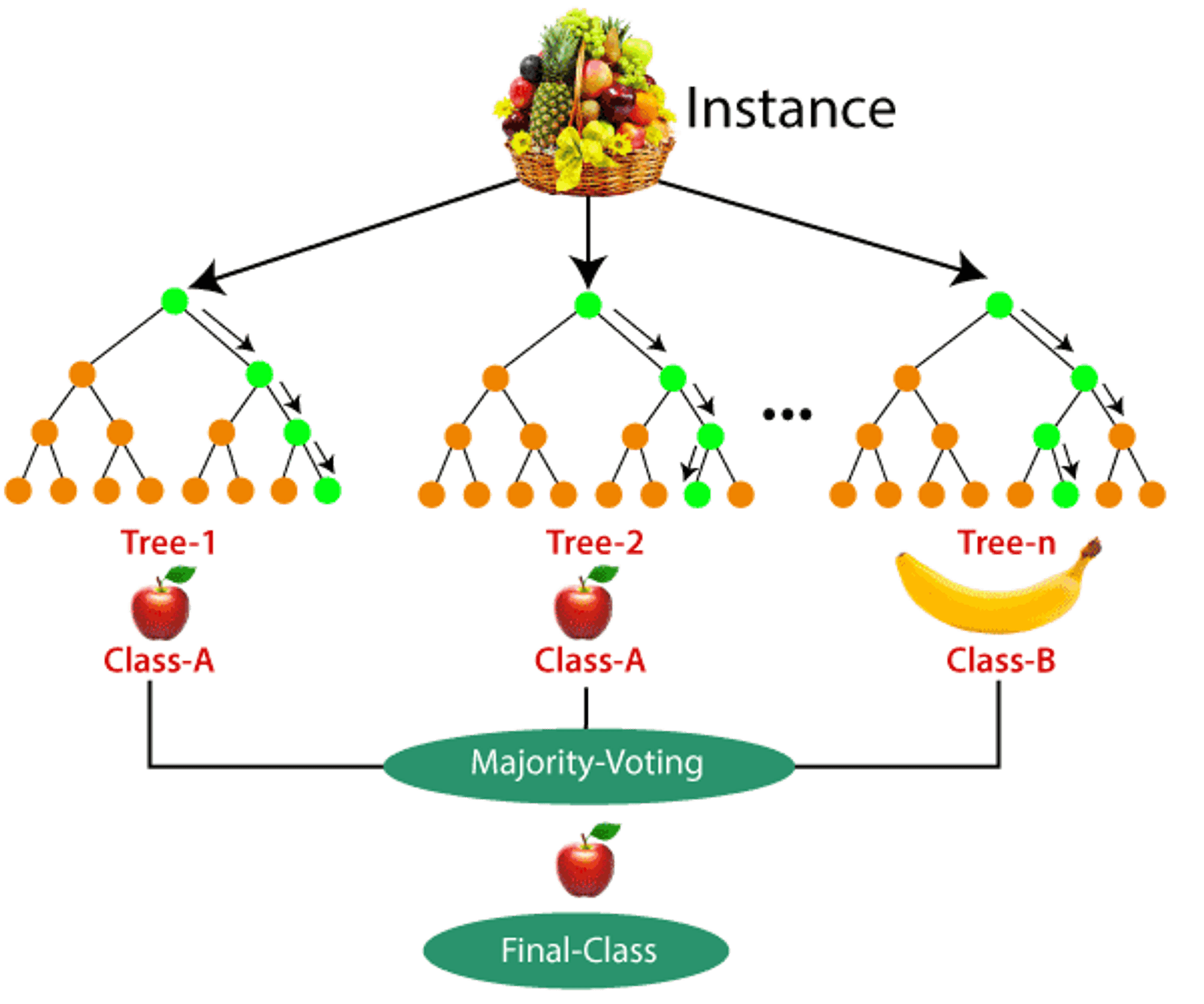
Principais Desvantagens do Random Forest
Apesar de suas qualidades, o Random Forest não é isento de desvantagens. Um ponto a considerar é a sua interpretabilidade. Embora seja possível avaliar a importância das variáveis, entender o raciocínio exato por trás de uma previsão específica pode ser desafiador, pois envolve a agregação de centenas ou milhares de árvores.
Outra desvantagem é o custo computacional. Treinar um grande número de árvores pode exigir mais tempo e recursos de processamento, especialmente com conjuntos de dados muito grandes. Isso pode ser um fator limitante em cenários com restrições de tempo ou hardware, como detalhado em discussões técnicas no GeeksforGeeks.
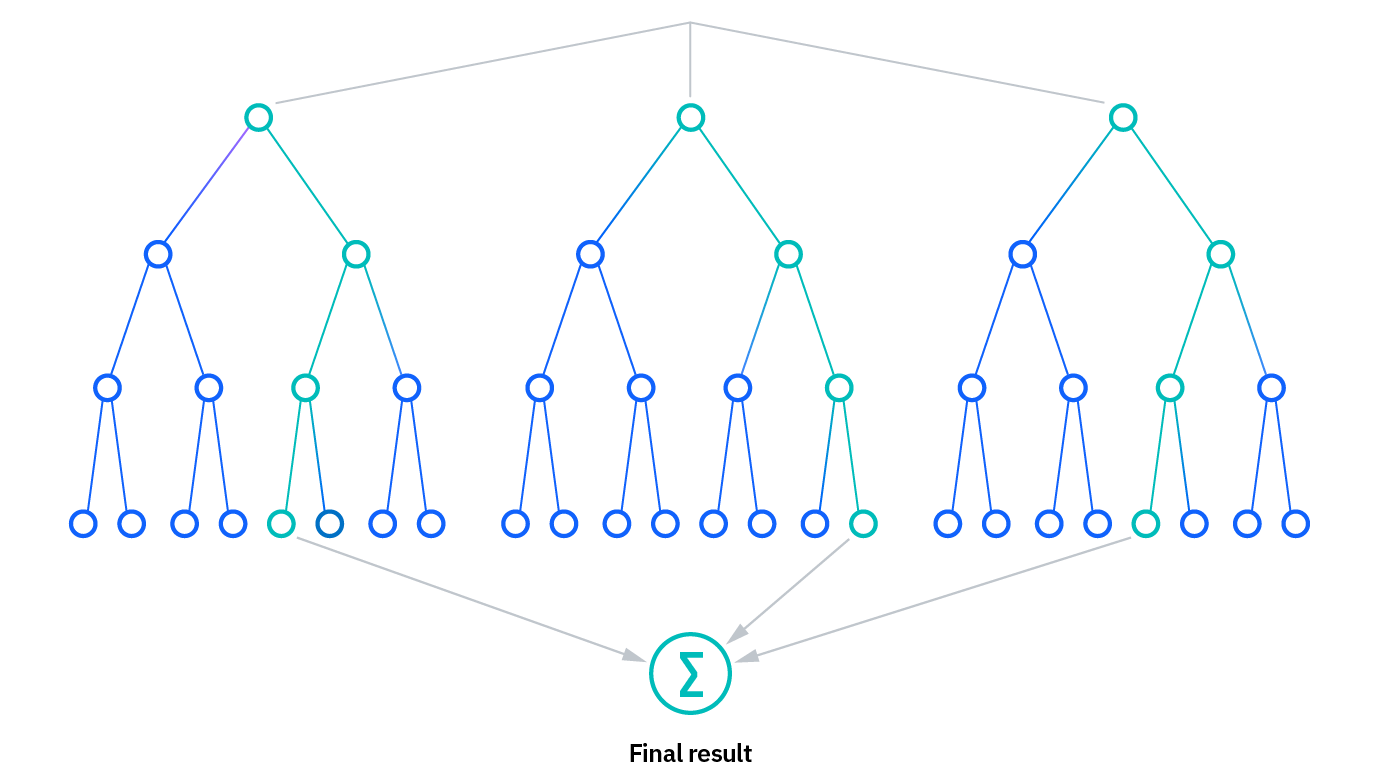
Aplicações Comuns do Random Forest
O Random Forest encontra aplicação em uma vasta gama de domínios. Na área da saúde, é usado para diagnóstico médico e descoberta de drogas. No setor financeiro, auxilia na detecção de fraudes e na previsão de risco de crédito. Em sistemas de recomendação, ajuda a prever as preferências do usuário.
Outros exemplos incluem análise de imagens, classificação de documentos, previsão de preços de imóveis e até mesmo em ecologia para modelar a distribuição de espécies. A sua versatilidade é um testemunho da sua eficácia, como explorado pela NVIDIA.
Implementação Prática em Python com Scikit-learn
Implementar o Random Forest em Python é surpreendentemente direto, graças à biblioteca Scikit-learn. Você pode criar um modelo de classificação com poucas linhas de código:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# Gerar dados de exemplo
X, y = make_classification(n_samples=1000, n_features=4, random_state=42)
# Dividir os dados em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Instanciar e treinar o modelo Random Forest
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
rf_classifier.fit(X_train, y_train)
# Fazer previsões
predictions = rf_classifier.predict(X_test)
Este exemplo demonstra a facilidade de uso, onde `n_estimators` define o número de árvores na floresta. Ajustar hiperparâmetros como este é fundamental para otimizar o desempenho do modelo, um tópico bem abordado em recursos como o da Didática Tech.
Comparativo: Random Forest vs. Outros Algoritmos de Ensemble
Comparado a outros métodos de ensemble, como o Gradient Boosting (e suas variações como XGBoost, LightGBM), o Random Forest tende a ser mais simples de ajustar e menos propenso a sobreajuste em configurações padrão. O Gradient Boosting constrói árvores sequencialmente, corrigindo os erros das árvores anteriores, o que pode levar a uma precisão ligeiramente maior em alguns casos, mas também exige mais cuidado na otimização.
Em relação ao AdaBoost, outro algoritmo popular de ensemble, o Random Forest geralmente oferece melhor desempenho em conjuntos de dados complexos e com muitas variáveis. AdaBoost foca mais em exemplos difíceis de classificar, enquanto o Random Forest se beneficia da diversidade criada pela aleatoriedade. A escolha entre eles muitas vezes depende das características específicas do problema e dos dados em mãos.
Random Forest: Um Aliado Poderoso na Análise de Dados
O Random Forest se estabeleceu como uma ferramenta indispensável no arsenal de qualquer cientista de dados. Sua combinação de precisão, robustez e relativa facilidade de uso o tornam ideal para uma vasta gama de aplicações. Embora a interpretabilidade possa ser um desafio em cenários muito específicos, os benefícios em termos de desempenho e insights geralmente compensam.
Se você busca um algoritmo que entregue resultados consistentes e confiáveis, especialmente em problemas de classificação e regressão com dados complexos, o Random Forest é, sem dúvida, uma escolha excelente. A sua capacidade de lidar com não-linearidades e interações complexas o coloca à frente de muitos outros métodos, justificando sua popularidade contínua no mercado.
Dicas Extras
- Aprofunde seus conhecimentos: Explore a fundo as métricas de avaliação para entender qual a melhor para o seu caso específico.
- Validação Cruzada é sua amiga: Sempre utilize validação cruzada para ter uma visão mais realista do desempenho do seu modelo em dados não vistos.
- Cuidado com o Overfitting: Embora o Random Forest seja robusto, ainda é possível cair em overfitting. Monitore o desempenho no conjunto de treino e teste.
- Feature Importance é ouro: Use a importância das features para entender quais variáveis realmente importam para a sua previsão.
Dúvidas Frequentes
O que é o algoritmo Random Forest?
O Random Forest, ou algoritmo floresta aleatória, é um método de aprendizado de máquina supervisionado que constrói múltiplas árvores de decisão durante o treinamento. Ele é usado tanto para tarefas de classificação quanto de regressão, oferecendo alta precisão e robustez.
Quando devo usar Random Forest?
É uma excelente escolha quando você precisa de um modelo com boa performance e que seja relativamente fácil de usar. Ele lida bem com grandes volumes de dados e muitas variáveis. Se você está começando com machine learning, a implementação random forest python é um ótimo ponto de partida.
Quais as vantagens do Random Forest?
As principais vantagens incluem a capacidade de lidar com dados ausentes, identificar a importância de variáveis, reduzir o overfitting comparado a uma única árvore de decisão e oferecer resultados precisos. É um algoritmo versátil.
Conclusão
Chegamos ao fim da nossa jornada pelo universo do algoritmo Random Forest. Agora você tem uma visão clara de como ele funciona e seu potencial. Lembre-se que a prática leva à perfeição. Explore mais sobre Random Forest vs Gradient Boosting para entender as nuances entre algoritmos poderosos e, quem sabe, aprofunde-se em como otimizar hiperparâmetros no Random Forest para extrair o máximo de seus projetos. O aprendizado contínuo é o que te levará mais longe!


