

Você se pergunta o que é o Apache Spark e como ele está moldando o futuro do Big Data em 2026? A verdade é que lidar com volumes massivos de dados pode ser um desafio, deixando muitas empresas para trás. Mas há uma solução poderosa que está redefinindo o processamento de dados em larga escala. Neste artigo, eu vou te mostrar como o Apache Spark não é apenas uma ferramenta, mas um motor unificado que impulsiona a inovação e a eficiência em cenários de Big Data. Prepare-se para entender por que ele se tornou fundamental.
Entendendo o Apache Spark: O Que o Torna Essencial para Big Data em 2026?
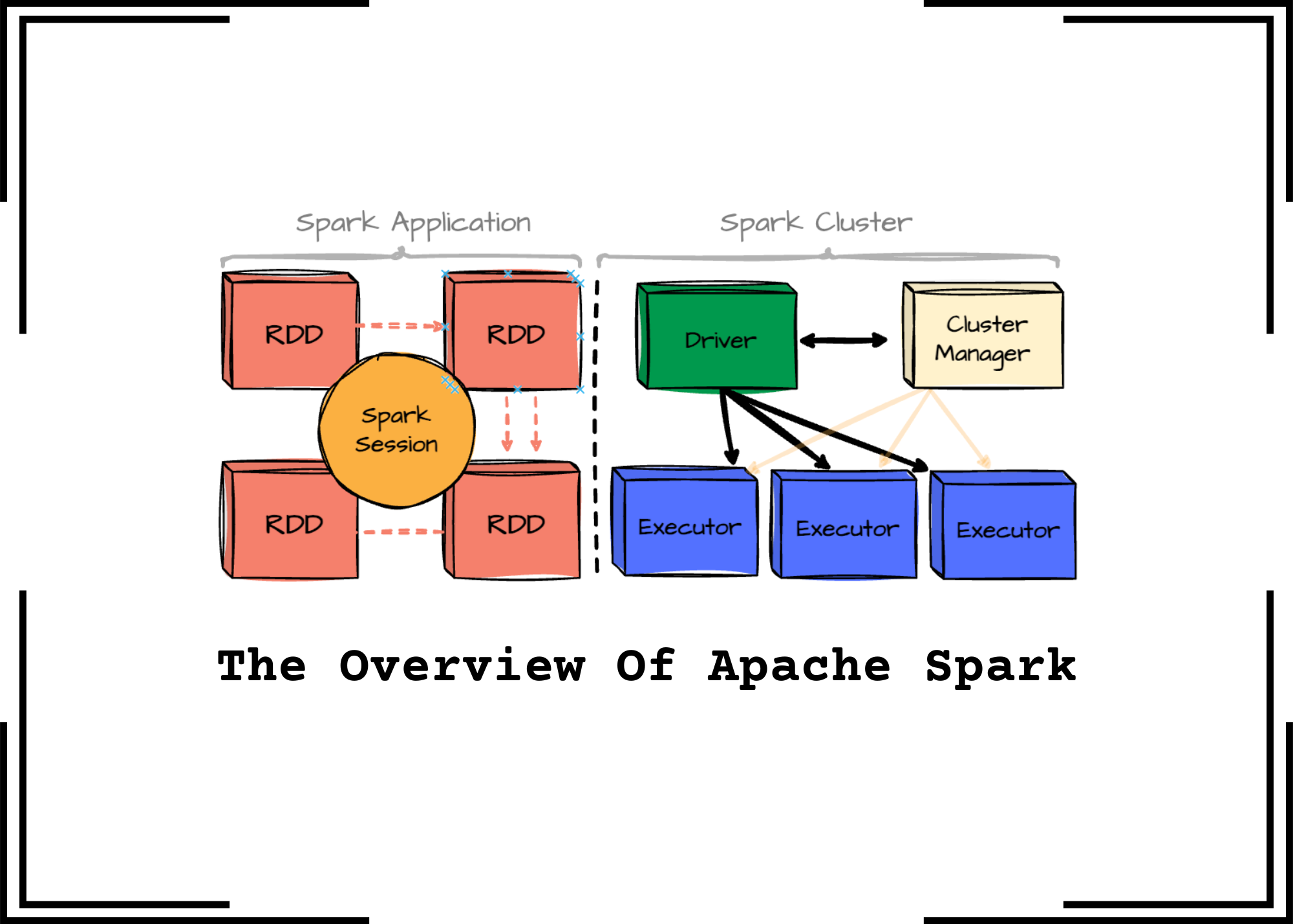
O Apache Spark é um motor unificado para processamento de dados em larga escala. Ele é a peça-chave no ecossistema de Big Data moderno.
Sua grande sacada é a velocidade. Diferente de tecnologias mais antigas como o Hadoop MapReduce, o Spark processa dados diretamente na memória.
Isso significa que ele é significativamente mais rápido, otimizando seu tempo e recursos.
“O Apache Spark é um motor de processamento de dados em código aberto, capaz de ser até 100 vezes mais rápido que o Hadoop MapReduce ao processar volumes massivos de informações diretamente na memória RAM.”
Apache Spark: O Motor Que Define o Big Data em 2026
No cenário atual de 2026, onde os dados fluem em volumes e velocidades sem precedentes, o Apache Spark se consolidou como a espinha dorsal do processamento de Big Data. Ele não é apenas uma ferramenta, mas um ecossistema unificado que permite lidar com diversas cargas de trabalho de forma eficiente e rápida. Se você trabalha com análise de dados, aprendizado de máquina ou qualquer área que envolva grandes volumes de informação, entender o Spark é fundamental.
O que torna o Spark tão especial é sua arquitetura que prioriza o processamento em memória, diferentemente de tecnologias mais antigas como o Hadoop MapReduce. Essa abordagem resulta em velocidades de processamento significativamente maiores, abrindo portas para análises em tempo real e interativas que antes eram inimagináveis.
Vamos desmistificar o que é o Apache Spark, como ele funciona e por que ele se tornou indispensável para empresas que buscam extrair valor real de seus dados.
| Característica | Descrição |
|---|---|
| Tipo | Motor unificado de processamento de dados em larga escala |
| Desempenho | Processamento em memória, significativamente mais rápido que Hadoop MapReduce |
| Componentes Principais | Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX |
| Linguagens Suportadas | Scala, Java, Python (PySpark), R, SQL |
| Ecossistemas | Executa em ambientes de nuvem como AWS, Google Cloud e Azure (Databricks) |
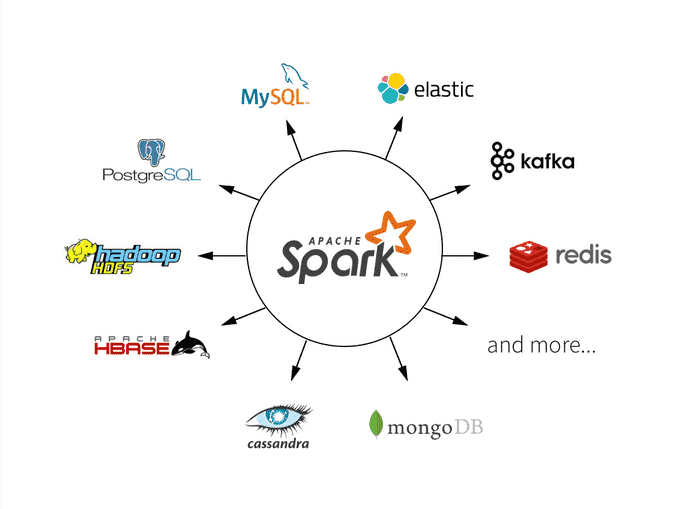
O que é o Apache Spark e sua Importância no Big Data
O Apache Spark é um framework de computação distribuída de código aberto, projetado para processar grandes conjuntos de dados de maneira rápida e escalável. Sua arquitetura foi pensada para otimizar a performance, utilizando discos apenas quando estritamente necessário e priorizando a RAM para as operações mais críticas. Essa característica o diferencia de sistemas anteriores, que dependiam pesadamente de operações em disco.
A importância do Spark no universo do Big Data reside em sua capacidade de unificar diversas tarefas de processamento de dados sob uma única plataforma. Isso simplifica a arquitetura de dados das empresas, reduzindo a complexidade e os custos associados à manutenção de múltiplos sistemas. Seja para análise exploratória, processamento batch, streaming em tempo real ou Machine Learning, o Spark oferece um conjunto robusto de ferramentas.
Em 2026, a capacidade de processar dados em tempo real e de forma interativa é um diferencial competitivo. O Spark entrega essa agilidade, permitindo que as organizações respondam mais rapidamente às mudanças do mercado, identifiquem tendências emergentes e tomem decisões baseadas em informações atualizadas. A escalabilidade do Spark garante que ele possa acompanhar o crescimento exponencial dos dados, sem comprometer o desempenho.

Velocidade e Desempenho: Spark vs. Hadoop MapReduce
A comparação entre Apache Spark e Hadoop MapReduce é crucial para entender a evolução do processamento de Big Data. O MapReduce, pioneiro no processamento distribuído, opera em fases sequenciais e depende fortemente da escrita e leitura de dados em disco entre cada etapa. Isso o torna relativamente lento para tarefas que exigem processamento iterativo ou interativo.
O Spark, por outro lado, revoluciona o desempenho ao manter os dados na memória RAM durante as iterações. Ele utiliza um conceito chamado Resilient Distributed Datasets (RDDs) e, posteriormente, DataFrames e Datasets, que permitem transformações e ações eficientes sem a necessidade constante de acesso ao disco. Essa arquitetura em memória pode resultar em velocidades até 100 vezes maiores para certas cargas de trabalho em comparação com o MapReduce.
Essa diferença de performance não é apenas teórica. Na prática, significa que análises complexas que levariam horas com MapReduce podem ser concluídas em minutos com Spark. Para aplicações como Machine Learning, que envolvem múltiplos ciclos de iteração sobre os dados, o ganho de velocidade proporcionado pelo Spark é transformador.
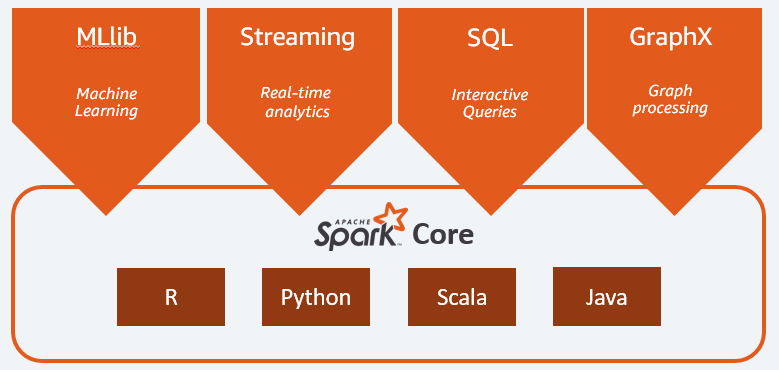
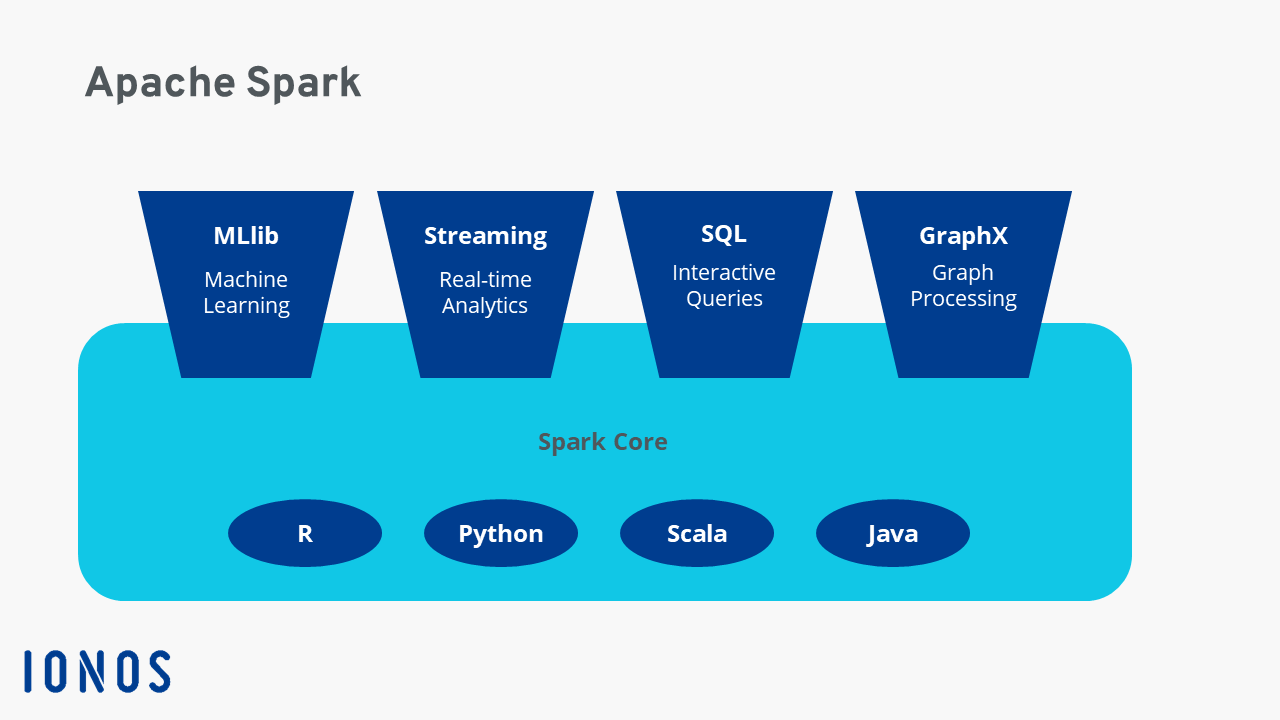
A Versatilidade do Spark: Componentes e Módulos (SQL, Streaming, MLlib, GraphX)
Um dos grandes trunfos do Apache Spark é sua arquitetura modular, que o torna uma ferramenta incrivelmente versátil. Ele não é um monólito, mas sim um motor unificado com componentes especializados para diferentes tipos de processamento de dados. Cada módulo foi desenvolvido para atender a necessidades específicas, mas todos se beneficiam da performance geral do Spark.
O Spark SQL, por exemplo, é um módulo poderoso para trabalhar com dados estruturados. Ele permite executar consultas SQL diretamente sobre os dados processados pelo Spark, facilitando a integração com ferramentas de Business Intelligence e a análise de dados relacionais. O Spark Streaming estende essa capacidade para o processamento de dados em tempo real, permitindo a análise de fluxos contínuos de dados de fontes como Kafka, Kinesis e Flume.
Para as necessidades de Inteligência Artificial, o MLlib (Machine Learning Library) oferece um conjunto abrangente de algoritmos de aprendizado de máquina. Isso inclui desde tarefas básicas como classificação e regressão até algoritmos mais avançados como clustering e sistemas de recomendação. Por fim, o GraphX é especializado no processamento de grafos, sendo ideal para analisar redes sociais, detecção de fraudes e sistemas de recomendação baseados em relações.
Linguagens de Programação Suportadas pelo Apache Spark (PySpark, Scala, Java, R, SQL)
A adoção generalizada do Apache Spark também se deve à sua flexibilidade em termos de linguagens de programação. O Spark oferece APIs para diversas linguagens populares, permitindo que equipes com diferentes especialidades colaborem e utilizem a ferramenta de forma eficaz. Isso democratiza o acesso ao poder do Big Data processing.
O PySpark, a API Python para Spark, é particularmente popular entre cientistas de dados e engenheiros de Machine Learning. Sua sintaxe familiar e a vasta biblioteca de pacotes Python facilitam a prototipagem e a implementação de modelos complexos. Desenvolvedores Java e Scala também encontram no Spark um ambiente poderoso para construir aplicações distribuídas de alta performance.
Além disso, o suporte a R e SQL amplia ainda mais o alcance do Spark. Analistas de dados podem usar suas habilidades em SQL para consultar e manipular grandes volumes de dados com a velocidade do Spark, enquanto usuários de R podem aproveitar o ecossistema de análise estatística em conjunto com o poder de processamento distribuído. Essa poliglota permite que quase qualquer profissional de dados se beneficie do Spark.

Principais Casos de Uso e Aplicações do Apache Spark
A aplicabilidade do Apache Spark em 2026 é vasta e impacta praticamente todos os setores. Empresas de todos os portes o utilizam para transformar dados brutos em insights acionáveis. Um dos casos de uso mais comuns é a análise de dados em larga escala, onde o Spark processa terabytes ou petabytes de dados para identificar padrões, tendências e anomalias.
No campo da Inteligência Artificial e Machine Learning, o Spark, com seu módulo MLlib, é fundamental para treinar modelos complexos. Isso inclui desde sistemas de recomendação personalizados para e-commerce, detecção de fraudes em transações financeiras, até diagnósticos médicos assistidos por IA. A velocidade do Spark acelera o ciclo de desenvolvimento e aprimoramento desses modelos.
O processamento de dados em tempo real, habilitado pelo Spark Streaming, é vital para aplicações que exigem respostas imediatas. Pense em monitoramento de redes sociais para análise de sentimento em tempo real, detecção de intrusão em sistemas de segurança, ou análise de dados de sensores em IoT (Internet das Coisas). O Spark permite que as empresas reajam instantaneamente a eventos em andamento, algo crucial em muitos negócios modernos.
Como o Apache Spark é Utilizado em Ambientes de Nuvem (AWS, Google Cloud, Azure)
A ascensão do Apache Spark está intrinsecamente ligada à popularidade das plataformas de computação em nuvem. Serviços como AWS, Google Cloud e Azure (com destaque para o Databricks, que foi fundado pelos criadores do Spark) oferecem ambientes gerenciados e escaláveis para executar o Spark.
Essas plataformas de nuvem simplificam drasticamente a implantação e o gerenciamento de clusters Spark. Em vez de se preocupar com a infraestrutura física, as empresas podem provisionar recursos computacionais sob demanda, pagando apenas pelo que usam. Isso reduz custos operacionais e permite que as equipes de dados se concentrem na análise e na construção de modelos, em vez de gerenciar servidores.
A integração do Spark com outros serviços de nuvem também é um grande benefício. Por exemplo, é comum usar o Spark para processar dados armazenados em serviços de armazenamento de objetos como Amazon S3, Google Cloud Storage ou Azure Blob Storage, e depois integrar os resultados com bancos de dados em nuvem ou ferramentas de visualização. Essa sinergia otimiza todo o pipeline de dados.
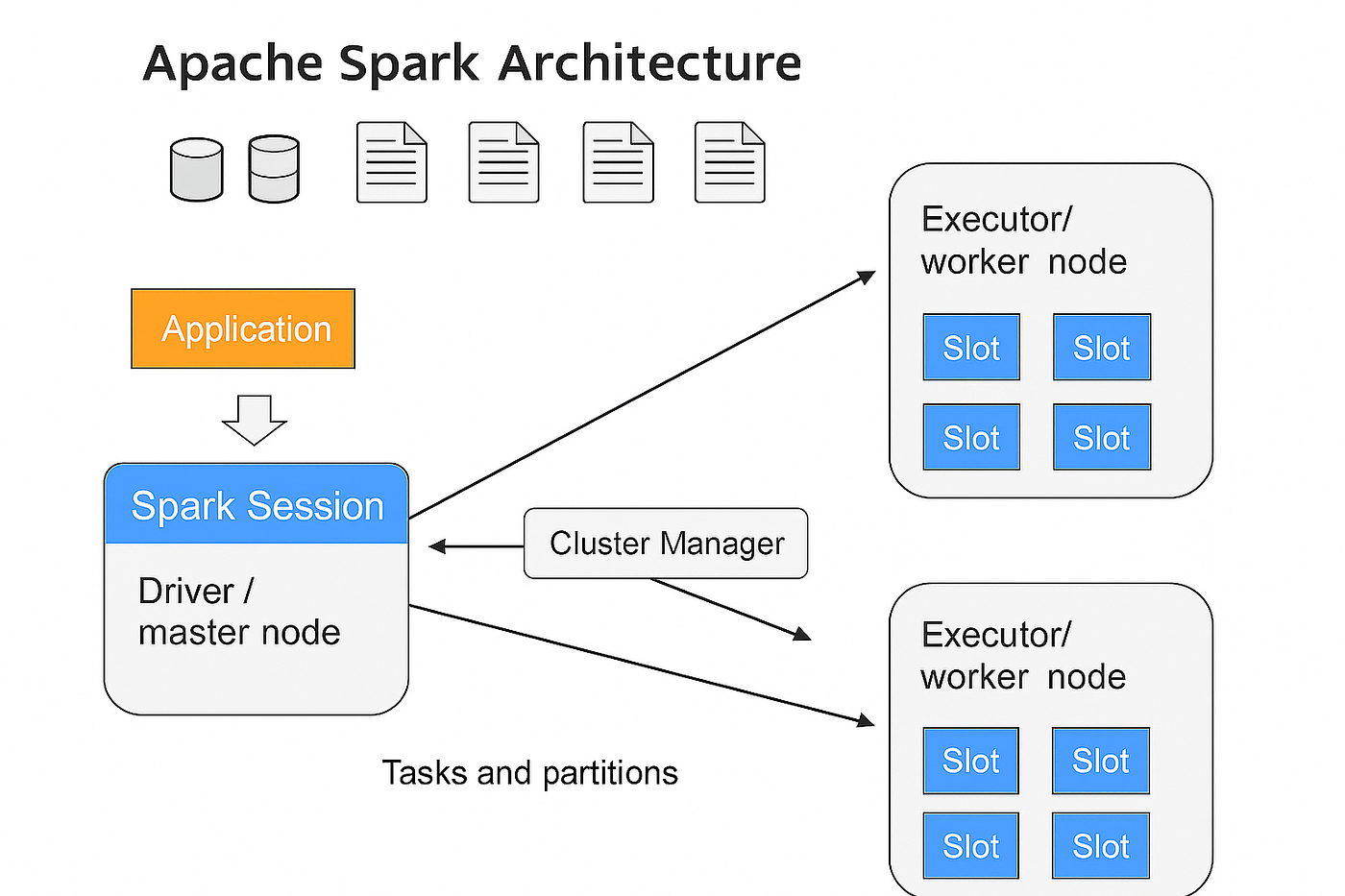
Spark SQL: Otimizando Consultas em Dados Estruturados
O Spark SQL representa um salto significativo na forma como interagimos com dados estruturados em ambientes de Big Data. Ele permite que você execute consultas SQL de forma nativa sobre os dados que o Spark está processando, seja de arquivos Parquet, JSON, Hive ou bancos de dados relacionais. Isso elimina a necessidade de converter dados para formatos específicos ou de usar ferramentas separadas para consultas SQL.
A otimização é um ponto chave. O Spark SQL utiliza um otimizador de consultas avançado chamado Catalyst, que analisa a consulta e o esquema dos dados para gerar um plano de execução eficiente. Ele pode realizar otimizações como pushdown de predicados (filtrar dados o mais cedo possível) e otimização de junções, resultando em tempos de resposta muito mais rápidos para consultas complexas.
Para profissionais que já estão familiarizados com SQL, o Spark SQL oferece uma curva de aprendizado suave. Você pode aproveitar seu conhecimento existente para explorar e analisar grandes volumes de dados de maneira interativa e performática, integrando facilmente a análise SQL com outras capacidades do Spark, como Machine Learning ou processamento de streaming.

Spark Streaming: Análise de Dados em Tempo Real
Em um mundo onde a informação em tempo real pode significar a diferença entre o sucesso e o fracasso, o Spark Streaming se torna um componente indispensável. Ele permite o processamento de fluxos de dados contínuos, recebendo dados de fontes em tempo real e aplicando transformações e análises à medida que os dados chegam.
O Spark Streaming opera com base no conceito de micro-batches. Ele coleta dados recebidos em curtos intervalos de tempo (por exemplo, a cada segundo) e os processa como pequenos lotes usando o motor principal do Spark. Embora não seja um processamento evento a evento puro, essa abordagem oferece um excelente equilíbrio entre latência e throughput, sendo suficiente para a vasta maioria das aplicações em tempo real.
A integração com fontes de dados populares como Kafka, Flume e Amazon Kinesis torna a ingestão de dados fluida. Isso permite que empresas monitorem atividades de usuários em websites, analisem dados de sensores de IoT em tempo real, detectem anomalias em transações financeiras e muito mais, tudo com a baixa latência que o Spark Streaming proporciona.
O Veredito do Especialista: O Spark Vale a Pena em 2026?
Sem sombra de dúvida, o Apache Spark não é apenas uma ferramenta valiosa, mas um componente essencial para qualquer organização que lida com Big Data em 2026. Sua combinação de velocidade, versatilidade e escalabilidade o posiciona como o padrão de fato para processamento de dados em larga escala.
O investimento em aprender e implementar Spark é recompensado com a capacidade de extrair insights mais profundos, tomar decisões mais rápidas e construir aplicações de dados inovadoras. A curva de aprendizado pode parecer um desafio inicial, mas os benefícios a longo prazo em termos de eficiência e capacidade analítica são imensuráveis. A vasta comunidade de código aberto e o suporte crescente em plataformas de nuvem garantem que o Spark continuará a evoluir e a dominar o cenário de Big Data nos próximos anos.
Dicas Extras
- Para começar: Se você está iniciando, foque em aprender PySpark. É a porta de entrada mais amigável para quem vem do Python e quer trabalhar com engenharia de dados.
- Performance é chave: Lembre-se que o Apache Spark é significativamente mais rápido que o Hadoop MapReduce, principalmente por processar dados em memória. Isso faz toda a diferença em workloads complexos.
- Ecossistema na nuvem: Explore como o Spark roda em ambientes como AWS, Google Cloud e Azure. Plataformas como Databricks facilitam muito a gestão e o uso.
- Streaming em tempo real: Se seu projeto envolve dados que chegam a todo momento, como em redes sociais ou monitoramento, o Spark Streaming é seu aliado.
- Machine Learning acessível: A biblioteca MLlib traz algoritmos de ML prontos para usar, simplificando a criação de modelos preditivos em larga escala.
Dúvidas Frequentes
O que é o Apache Spark e como funciona?
O Apache Spark é um motor de processamento de dados unificado, projetado para lidar com grandes volumes de informação de forma rápida e eficiente. Ele funciona distribuindo tarefas por um cluster de computadores, processando dados em memória RAM sempre que possível, o que o torna muito mais veloz que tecnologias anteriores como o Hadoop MapReduce. Ele possui módulos para SQL, streaming, machine learning e processamento de grafos.
Quais as principais vantagens do Apache Spark para Big Data?
As principais vantagens incluem sua velocidade superior, a capacidade de realizar processamento em lote e em tempo real (com Spark Streaming), a facilidade de uso com APIs em diversas linguagens (como PySpark), e um ecossistema rico com bibliotecas para Machine Learning (MLlib) e consultas SQL (Spark SQL). Ele unifica diversas workloads facilmente.
Apache Spark é melhor que Hadoop MapReduce?
Em termos de performance, o Apache Spark geralmente supera o Hadoop MapReduce. Isso se deve principalmente à sua capacidade de processar dados em memória, enquanto o MapReduce depende mais de operações em disco. Para a maioria das aplicações de Big Data modernas, o Spark oferece uma solução mais ágil e eficiente.
Conclusão
O Apache Spark se consolidou como uma ferramenta indispensável no universo de Big Data. Sua arquitetura unificada e a velocidade de processamento abrem portas para análises mais profundas e em tempo real. Para quem deseja se destacar na área, explorar o Comparativo: Apache Spark vs Hadoop MapReduce para Big Data pode trazer clareza sobre as evoluções, e mergulhar em um Guia Completo de PySpark para Iniciantes em Data Science é um passo estratégico para aplicar todo esse poder na prática.


