

O que é o Apache Hadoop? Se você trabalha com muitos dados, sabe como é difícil gerenciar tudo. O Hadoop é um sistema feito para lidar com grandes volumes de informação de forma distribuída. Neste post, eu te explico como ele funciona e por que ele é tão útil para empresas.
Desvendando o Apache Hadoop: O Coração da Big Data
O Apache Hadoop é uma estrutura de código aberto essencial para lidar com grandes volumes de dados, o chamado Big Data. Ele permite armazenar e processar quantidades massivas de informação de forma distribuída em clusters de computadores. Pense nele como um sistema que consegue gerenciar montanhas de dados sem se perder, distribuindo o trabalho entre várias máquinas para que tudo fique mais rápido e eficiente.
O grande barato do Hadoop é sua capacidade de processar dados em lote e em tempo real. Ele se tornou a espinha dorsal para muitas empresas que precisam analisar desde registros de clientes até dados de sensores, extraindo valor e insights que antes eram impossíveis de obter. É uma ferramenta poderosa para quem quer ir além do comum na análise de informações.
Confira este vídeo relacionado para mais detalhes:
O Que é o Apache Hadoop e Por Que Você Deveria Saber
A Base da Análise de Dados Massivos: O Que o Hadoop Faz?
O grande lance do Hadoop é que ele foi pensado para lidar com arquivos grandes e complexos, distribuindo o trabalho por vários computadores. Isso significa que, em vez de ter um supercomputador tentando fazer tudo sozinho (o que seria caríssimo e lento), o Hadoop divide a tarefa. Ele tem componentes que garantem que os dados fiquem seguros, mesmo que um computador falhe. E o mais importante: ele permite que a gente rode análises sobre esses dados distribuídos de forma paralela, acelerando muito o processo de extrair valor. É essa capacidade de trabalhar em grande escala que o torna indispensável.
Quando você ouve falar de “Big Data”, o Hadoop geralmente está lá no meio. Ele é o motor que possibilita a análise dessas grandes quantidades de dados para descobrir padrões, fazer previsões e tomar decisões mais inteligentes. Seja para entender o comportamento do consumidor, otimizar rotas de entrega ou até mesmo avançar na pesquisa científica, o Hadoop é o alicerce. Ele democratizou o acesso ao processamento de dados em larga escala, tornando isso acessível para muitas empresas e pesquisadores.
Dica Prática: Se você está começando a se aprofundar em análise de dados, entender como o Hadoop funciona, mesmo que superficialmente, vai te dar uma visão clara de como as grandes empresas lidam com suas informações.

HDFS: O Sistema de Arquivos Distribuído Que Permite Armazenar Gigantes

O HDFS é fundamental para lidar com Big Data. Ele foi projetado para ser confiável e eficiente. Cada pedaço de arquivo é copiado várias vezes em diferentes máquinas. Se um servidor der problema, o sistema automaticamente usa outra cópia. Isso garante que seus dados estejam sempre disponíveis e que o processamento não pare. É essa arquitetura distribuída que faz toda a diferença para armazenar terabytes ou petabytes sem dor de cabeça.
Usar o HDFS significa que você pode armazenar e gerenciar petabytes de informações sem se preocupar com o limite de um único servidor. É a base para muitas aplicações que precisam processar grandes volumes de dados de forma robusta.
Dica Prática: Ao trabalhar com Hadoop, lembre-se que o HDFS é otimizado para grandes arquivos. Seus arquivos pequenos podem não ter o mesmo desempenho. Tente agrupá-los sempre que possível.

MapReduce: O Motor Que Processa Seus Dados em Paralelo
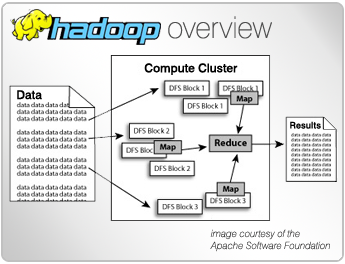
Sabe quando você tem um monte de informações para analisar, tipo um montão mesmo? O MapReduce é o jeito que o Hadoop usa para processar tudo isso de forma inteligente. Pensa nele como um maestro que divide uma tarefa grande em várias menores e distribui para vários “músicos” (computadores) tocarem ao mesmo tempo. Ele tem duas fases principais: o “Map” e o “Reduce”. No Map, ele pega os dados brutos e os transforma em algo mais fácil de trabalhar, criando pares de chave-valor. Já no Reduce, ele junta esses resultados parciais para chegar na resposta final que você quer.

Essa capacidade de processar em paralelo é o que faz o MapReduce ser tão eficiente. Em vez de um único computador levar horas ou dias para analisar gigabytes ou terabytes de dados, o MapReduce espalha o trabalho por uma rede de máquinas. Isso significa que você obtém resultados muito mais rápido. Ele é a inteligência por trás de como o Apache Hadoop gerencia e processa esses enormes conjuntos de dados que encontramos hoje em dia, desde redes sociais até sistemas de recomendação.
É essa arquitetura que permite que o Hadoop seja uma ferramenta tão robusta para lidar com Big Data. O MapReduce não é só uma teoria; é a força motriz que faz a mágica acontecer nos bastidores quando você está trabalhando com grandes volumes de informação.
Dica Prática: Ao trabalhar com MapReduce, pense em como você pode quebrar seus dados de entrada em pedaços menores e como a etapa de “Reduce” pode agrupar eficientemente os resultados intermediários para obter a informação final mais rapidamente.
YARN: O Gerenciador de Recursos Essencial Para o Hadoop
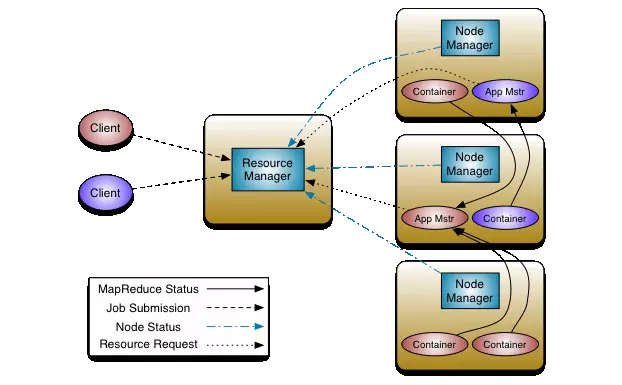
Se você tá se perguntando “o que é o Apache Hadoop” e como ele lida com um monte de dados, saiba que o YARN é o cérebro por trás disso. Pense nele como o maestro de uma orquestra gigante. Ele não executa as tarefas diretamente, mas organiza quem faz o quê e quando. Antes do YARN, o Hadoop tinha um JobTracker que fazia tudo, mas ficava sobrecarregado. O YARN separou essas funções, tornando tudo mais eficiente e escalável.
O YARN funciona com dois componentes principais: o ResourceManager e o NodeManager. O ResourceManager é o “chefe” que gerencia os recursos de todo o cluster Hadoop. Ele decide quais aplicações podem rodar e quantos recursos (CPU, memória) cada uma recebe. Já o NodeManager fica em cada máquina do cluster e é responsável por monitorar os recursos daquela máquina específica e executar os contêineres de aplicação solicitados pelo ResourceManager. Essa divisão é o que permite que diferentes tipos de aplicações rodem no Hadoop, não só MapReduce.
Com o YARN, o Hadoop se tornou uma plataforma mais flexível. Agora, você pode rodar não só o MapReduce, mas também outras ferramentas como o Spark, Flink, e até mesmo aplicações de bancos de dados NoSQL. Isso significa que seu investimento em Hadoop se torna muito mais versátil. Essa arquitetura moderna permite que as empresas processem e analisem grandes volumes de dados de forma muito mais ágil e com diferentes tipos de carga de trabalho.
Dica Prática: Ao configurar seu cluster Hadoop, preste atenção nas configurações do YARN. Ajustar o `yarn.nodemanager.resource.memory-mb` e `yarn.nodemanager.resource.cpu-vcores` pode fazer uma grande diferença na performance geral e na forma como suas aplicações utilizam os recursos do cluster.
Hadoop Versão 1 vs. Versão 2: Entendendo a Evolução
Muita gente sabe o que é o Apache Hadoop, mas nem sempre se lembra que ele passou por mudanças importantes. A versão 1 era o começo, focada em tarefas simples de processamento de dados em larga escala. Pense nela como a fundação, que estabeleceu a base para o que viria depois. Era bom para o que se propunha, mas tinha suas limitações.
A grande virada veio com o Hadoop Versão 2. Foi aí que o jogo mudou de verdade. Eles introduziram o YARN (Yet Another Resource Negotiator). Sabe o que isso significa na prática? O YARN separou a gestão de recursos (quem usa o quê) da execução das tarefas. Isso deu uma flexibilidade absurda, permitindo que outros frameworks trabalhassem junto com o Hadoop, não apenas o MapReduce de sempre. Imagina poder rodar diferentes tipos de processamento na mesma infraestrutura!
Essa separação, com o YARN gerenciando o show, tornou o Hadoop Versão 2 muito mais escalável e versátil. Ele deixou de ser apenas uma ferramenta para um propósito e se tornou uma plataforma mais robusta. Você consegue rodar tanto processamento batch quanto aplicações em tempo real, ou até mesmo machine learning, de forma mais eficiente. Pois é, a diferença entre uma versão e outra é gigantesca para quem lida com grandes volumes de dados.
Dica Prática: Ao planejar a migração ou a adoção de Hadoop, sempre verifique se o seu ambiente e as suas necessidades se alinham melhor com as capacidades da versão 2, especialmente por causa do YARN.
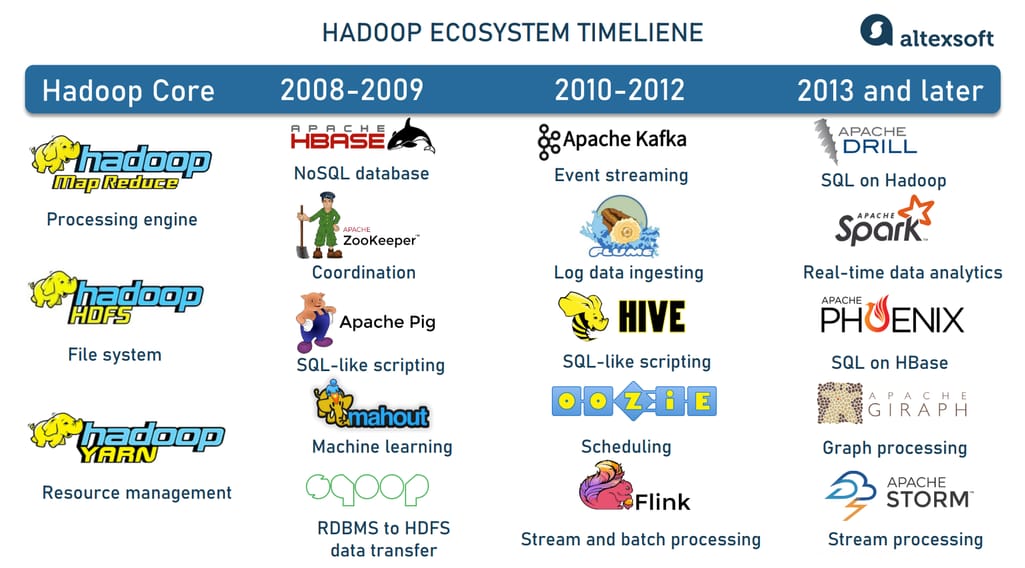
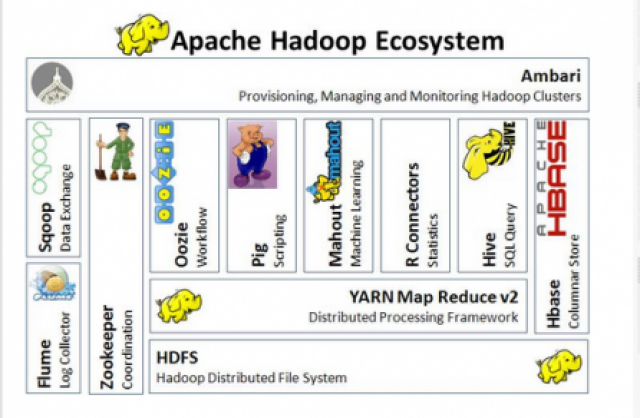
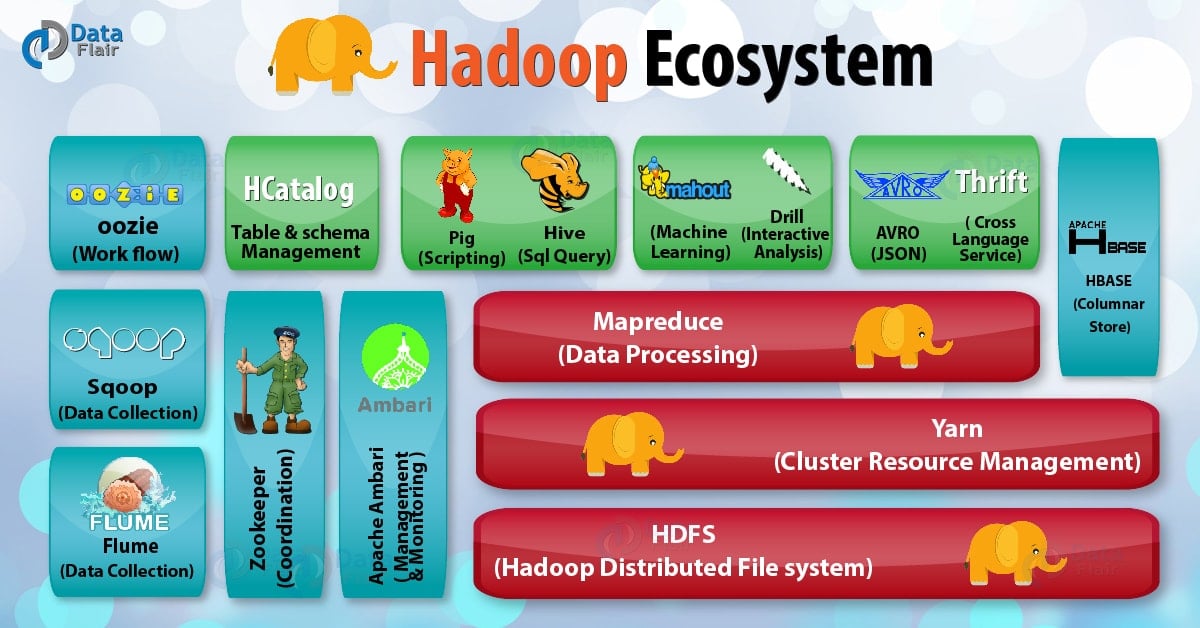
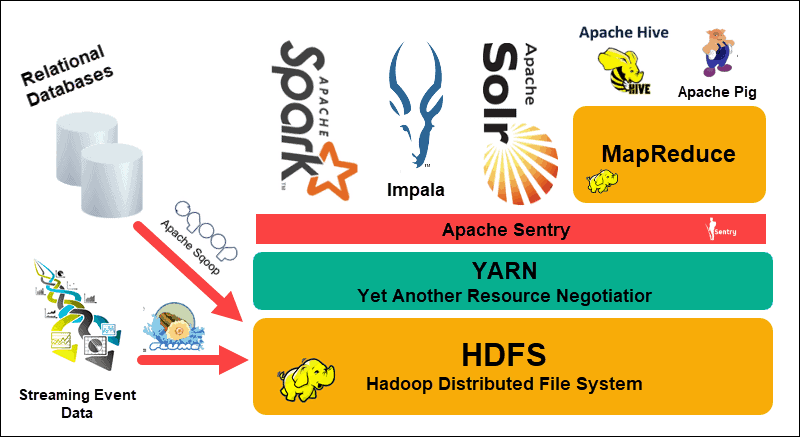
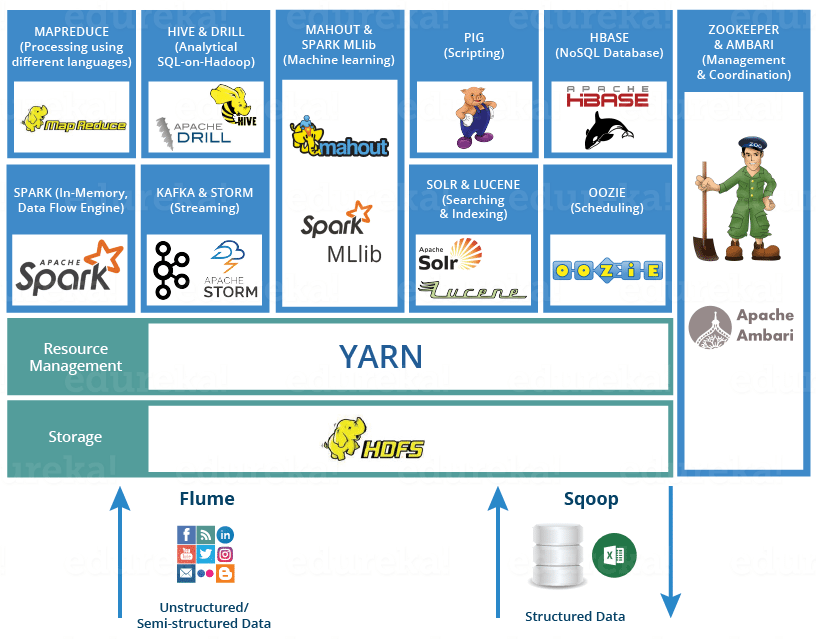
Ecossistema Hadoop: Ferramentas Que Ampliam Seus Poderes
Se você trabalha ou tem curiosidade sobre grandes volumes de dados, o Apache Hadoop é um nome que você vai ouvir muito. Pense nele como uma base sólida para armazenar e processar informações que não caberiam em um único computador. Ele é projetado para rodar em clusters de máquinas, o que significa que ele distribui o trabalho, tornando tudo mais rápido e confiável. É a espinha dorsal para muita análise de dados hoje em dia.

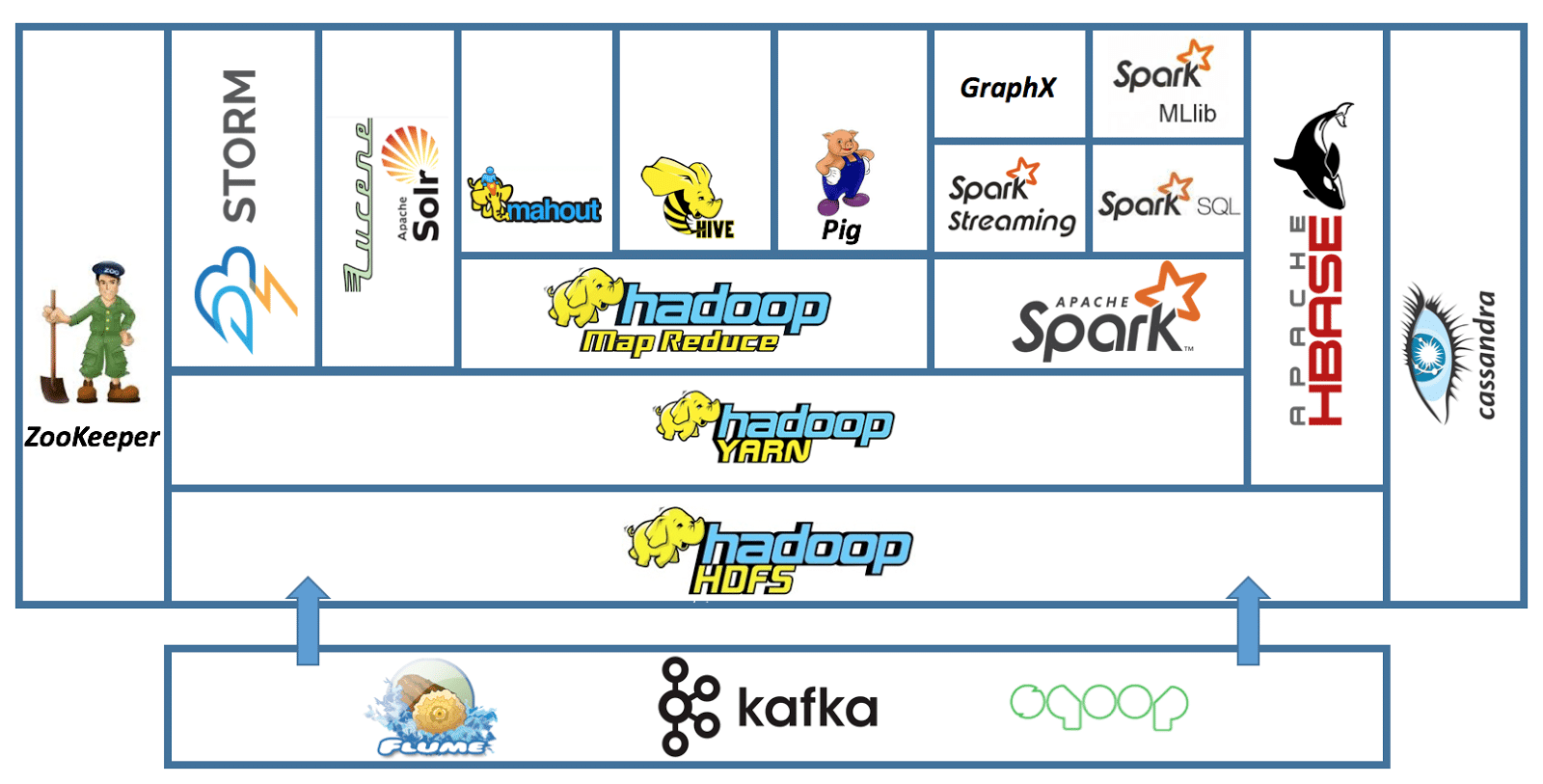
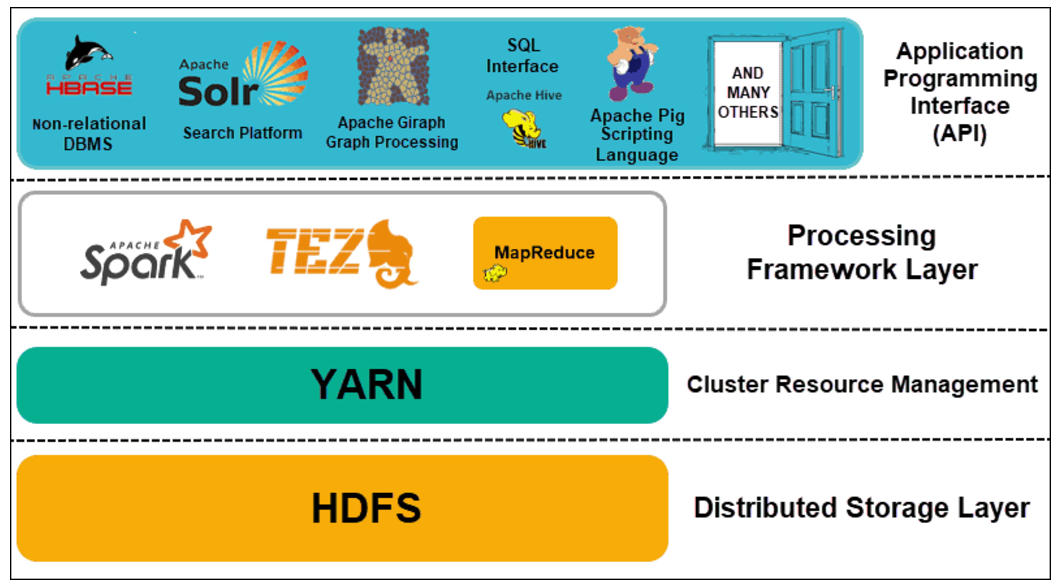
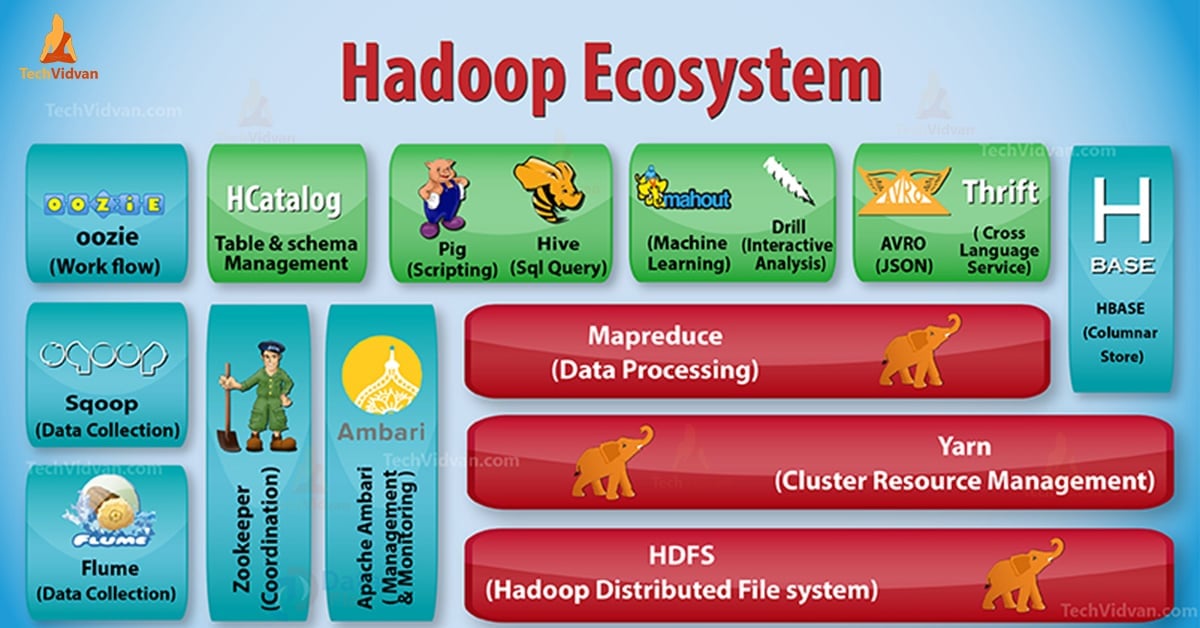
Mas o Hadoop, por si só, é só o começo. O que realmente faz a mágica acontecer é o seu ecossistema. Temos ferramentas como o Hive, que permite fazer consultas em grandes conjuntos de dados usando algo parecido com SQL. Para quem gosta de um processamento mais dinâmico, o Spark surge como um concorrente forte, sendo ainda mais rápido em muitos casos. E não podemos esquecer do Pig, uma linguagem de script para manipular dados. Cada uma dessas ferramentas se encaixa e amplia o que você consegue fazer com os seus dados.
A beleza do ecossistema Hadoop é que ele não te prende a uma única forma de trabalhar. Você pode escolher as ferramentas que melhor se adaptam ao seu tipo de tarefa. Se você precisa de agilidade no processamento, o Spark pode ser seu aliado. Se as consultas complexas em SQL são seu forte, o Hive vai te atender bem. É essa flexibilidade que torna o Hadoop tão relevante. Vamos combinar, ter um leque de opções para lidar com dados é fundamental.
Dica Prática: Ao começar com Hadoop, experimente o HDFS para armazenamento e o MapReduce para tarefas mais simples. Depois, explore o Hive para consultas e o Spark para processamentos que exigem mais velocidade.
Hadoop e o Business Intelligence: Uma Dupla Imbatível
Quando falamos de Business Intelligence (BI), estamos falando de usar dados para tomar decisões melhores no seu negócio. O Hadoop entra aí como um motor potente para lidar com esses dados. Ele não só armazena, mas também processa dados de diversas fontes, como redes sociais, logs de servidores, sensores, e por aí vai. Isso significa que você pode ter uma visão muito mais completa do seu mercado e dos seus clientes.
A beleza do Hadoop está em sua capacidade de escalabilidade. Se você precisa analisar mais dados, é só adicionar mais “nós” (computadores) ao seu cluster. Ele é construído para ser resiliente, ou seja, se um computador falhar, os outros continuam trabalhando sem problemas. Essa arquitetura é fundamental para empresas que geram e precisam analisar terabytes ou petabytes de informação, algo que ferramentas tradicionais teriam dificuldade em gerenciar eficientemente.
Integrar o Hadoop com suas ferramentas de BI abre um leque de possibilidades. Você pode criar dashboards mais dinâmicos, realizar análises preditivas mais precisas e identificar tendências ocultas. O Hadoop cuida da parte pesada do processamento, liberando suas ferramentas de BI para focarem na visualização e na entrega de insights acionáveis.
Dica Prática: Se você está começando a explorar o Hadoop para BI, comece com um projeto pequeno e bem definido. Foque em um conjunto de dados específico e em uma pergunta de negócio clara para aprender o básico antes de escalar.

Casos de Uso Reais do Hadoop no Dia a Dia
Muita gente ouve falar de “Big Data” e pensa em algo distante, coisa de cientista de dados em laboratórios. Mas a verdade é que ferramentas como o Apache Hadoop já estão atuando nos bastidores de muitas coisas que usamos. Pense no Hadoop como uma caixa de ferramentas gigante, projetada para lidar com volumes imensos de dados de uma só vez, algo que computadores comuns não dariam conta. Ele não é um programa único, mas um conjunto de softwares que trabalham juntos para armazenar e processar esses dados.

Onde você vê isso na prática? Vamos lá: serviços de streaming de vídeo, como Netflix ou YouTube, usam Hadoop para analisar o que você assiste, o que te faz gostar de um tipo de conteúdo e o que pode te interessar a seguir. Da mesma forma, bancos e instituições financeiras o utilizam para detectar fraudes, analisando milhões de transações em tempo real. Até mesmo em redes sociais, ele ajuda a personalizar seu feed, entendendo seus interesses com base nas suas interações.
Outro exemplo são as empresas de varejo, que usam o Hadoop para analisar o comportamento de compra dos clientes, planejar estoques e até prever tendências de mercado. Isso permite que elas ofereçam promoções mais certeiras e produtos que você realmente procura. Ou seja, o “o que é o Apache Hadoop” se traduz em inteligência por trás de muitas conveniências modernas.
Dica Prática: Se você usa algum serviço online que parece “adivinhar” o que você quer, é bem provável que uma tecnologia como o Hadoop esteja envolvida na análise dos seus dados para entregar essa experiência personalizada.

Segurança no Hadoop: Protegendo Suas Informações Valiosas
O Apache Hadoop é uma ferramenta incrível para lidar com grandes volumes de dados, mas vamos combinar, ninguém quer que essas informações caiam em mãos erradas. Por isso, a segurança é um ponto crucial. O Hadoop, por si só, oferece algumas camadas de proteção, mas o segredo é saber como configurá-las e usá-las a seu favor. Pense nisso como colocar um bom cadeado na sua casa: a casa já tem a estrutura, mas o cadeado é o que realmente impede os intrusos.

Quando falamos de segurança no Hadoop, estamos pensando em coisas como autenticação, autorização e criptografia. A autenticação garante que só quem diz ser, realmente é. A autorização define o que cada usuário pode ou não pode fazer com os dados. E a criptografia embaralha as informações para que, mesmo que alguém as intercepte, não consiga ler nada. É como enviar uma carta com um código secreto: só quem sabe a chave entende a mensagem.
Para garantir que seus dados no Hadoop estejam seguros, é essencial implementar políticas de acesso rigorosas. Isso significa definir quem tem permissão para ler, escrever ou excluir arquivos. Além disso, manter o sistema sempre atualizado com os últimos patches de segurança é fundamental. Fique atento às ferramentas de auditoria, elas te ajudam a rastrear qualquer atividade suspeita. Dica Prática: Use o Kerberos para autenticação, ele é um padrão de mercado e oferece uma camada robusta de segurança para o seu cluster Hadoop.
Aprendendo Hadoop: Por Onde Começar Sua Jornada
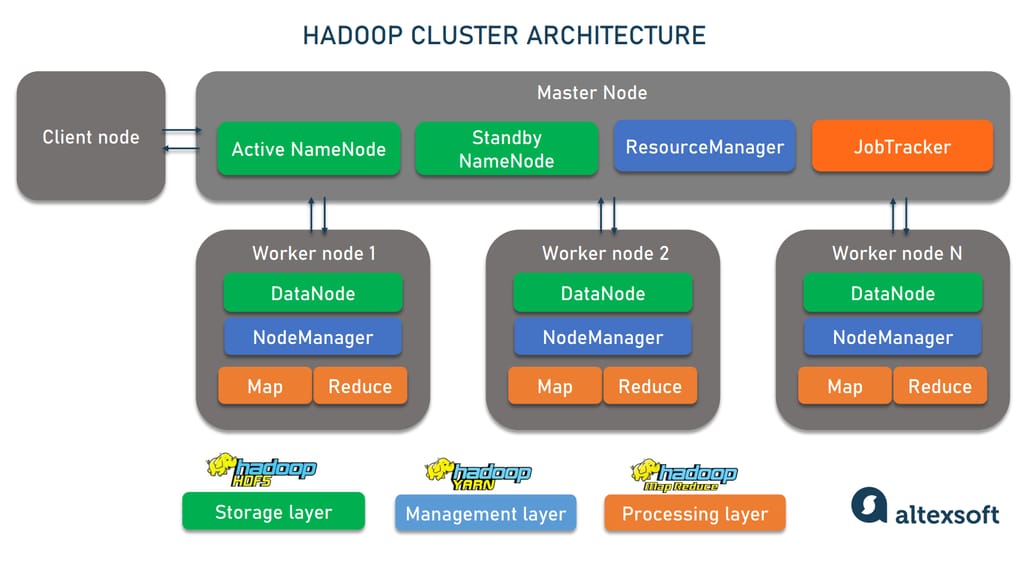
Você já ouviu falar sobre o Apache Hadoop? Se você lida com grandes volumes de dados, seja em uma empresa ou até mesmo em projetos pessoais, precisa conhecer essa ferramenta. Basicamente, o Hadoop é um framework de código aberto criado para armazenar e processar conjuntos de dados gigantescos de forma distribuída. Pense nele como um sistema que permite que você trabalhe com informações muito maiores do que um único computador conseguiria gerenciar. Ele divide o trabalho entre vários computadores (nós) em um cluster, tornando o processamento mais rápido e eficiente.
O grande trunfo do Hadoop está em sua arquitetura. Ele é composto principalmente por duas partes: o HDFS (Hadoop Distributed File System) e o MapReduce. O HDFS é o sistema de arquivos que distribui os dados por todos os nós do cluster, garantindo que nada se perca e que os dados estejam disponíveis mesmo se um nó falhar. Já o MapReduce é o motor de processamento que executa as tarefas em paralelo nesses dados. É essa combinação que permite lidar com petabytes de informação sem suar a camisa.
Para começar a entender o Hadoop, o ideal é focar nos conceitos básicos primeiro. Não se assuste com a complexidade inicial, pois com a prática as coisas ficam mais claras. Procure entender como ele gerencia o armazenamento e o processamento. Existem muitas distribuições e ferramentas que facilitam o uso, como o Cloudera ou o Hortonworks (agora parte do Cloudera), que simplificam a instalação e configuração.
Dica Prática: Para testar o Hadoop sem precisar de um cluster físico, baixe uma máquina virtual pré-configurada ou use um ambiente sandbox. Isso permite que você experimente os comandos e entenda o fluxo de trabalho em um ambiente controlado.
Com certeza! Vamos desmistificar o Apache Hadoop com uma tabela bem explicativa.
Os Pilares do Hadoop: Mais Que Armazenamento
| Item | Características Principais | Para que serve no dia a dia | Dicas do Autor |
|---|---|---|---|
| A Base da Análise de Dados Massivos: O Que o Hadoop Faz? | Permite armazenar e processar grandes volumes de dados de diversas fontes, de forma distribuída e tolerante a falhas. | Ajuda empresas a entenderem o comportamento de clientes, prever tendências e tomar decisões mais assertivas com base em muitos dados. | Pense no Hadoop como um grande armazém que não só guarda tudo, mas também tem um exército de ajudantes para organizar e analisar. |
| HDFS: O Sistema de Arquivos Distribuído Que Permite Armazenar Gigantes | Divide arquivos grandes em blocos e os distribui por vários computadores (nós) em um cluster. Se um nó falha, os dados ainda estão seguros em outros. | Garante que seus dados, não importa o tamanho, sejam armazenados de forma segura e acessível, mesmo que parte do sistema caia. | É como ter vários cadernos em vez de um só. Se um sumir, você não perde tudo. E cada caderno tem um pedacinho do seu trabalho. |
| MapReduce: O Motor Que Processa Seus Dados em Paralelo | Um modelo de programação que divide tarefas complexas em pequenas partes (map) e depois as combina (reduce) para obter o resultado final, tudo feito ao mesmo tempo em vários nós. | Acelera a análise de dados que levariam dias ou semanas para serem processados em um único computador. | Imagine várias pessoas lendo o mesmo livro e anotando as coisas importantes em partes diferentes. Depois, juntam todas as anotações para ter um resumo completo. |
| YARN: O Gerenciador de Recursos Essencial Para o Hadoop | Gerencia os recursos computacionais do cluster (CPU, memória) e agenda as tarefas de processamento. Ele é o “maestro” que coordena tudo. | Garante que diferentes aplicações Hadoop rodem de forma eficiente no mesmo cluster, sem conflitos, usando os recursos disponíveis. | Pense no YARN como o gerente de um restaurante. Ele decide quem cozinha o quê e quando, para que tudo saia perfeito e a cozinha não fique parada. |
| Hadoop Versão 1 vs. Versão 2: Entendendo a Evolução | A Versão 1 tinha o MapReduce integrado ao HDFS. A Versão 2 separou o processamento (MapReduce) da gestão de recursos (YARN), tornando o sistema mais flexível e permitindo outros tipos de processamento. | A Versão 2 abriu as portas para novas ferramentas e tipos de análise, tornando o Hadoop mais versátil para diversas necessidades. | A mudança é como de um carro que só faz uma coisa para um veículo modular que pode ser adaptado para transportar carga ou pessoas. |
| Ecossistema Hadoop: Ferramentas Que Ampliam Seus Poderes | Conjunto de projetos e ferramentas (como Hive, Pig, Spark, HBase) que se integram ao Hadoop para facilitar a análise, o armazenamento e a manipulação |
Confira este vídeo relacionado para mais detalhes:
Aplicações Práticas do Hadoop Que Você Vê Todo Dia
Pois é, o Hadoop não é só um bicho-papão da informática. Ele está por trás de muita coisa que você usa e nem percebe. Quero te mostrar como essa tecnologia impacta seu dia a dia.
Vamos lá, se liga nessas dicas de como o Hadoop aparece na sua vida:
- Recomendações Personalizadas: Sabe quando um serviço de streaming te sugere um filme ou uma loja online mostra produtos que você pode gostar? O Hadoop processa toneladas de dados para entender seus gostos e te dar essas sugestões. É ele que faz o “match” perfeito.
- Redes Sociais: Analisar o que tá bombando, as tendências, os assuntos mais comentados. Tudo isso envolve o processamento de um volume gigantesco de informações. O Hadoop ajuda a organizar e entender esse mar de dados para você ver o que é relevante.
- Serviços Financeiros: Detecção de fraudes, análise de risco, personalização de ofertas bancárias. Por trás de um atendimento mais seguro e eficiente, muitas vezes tem o Hadoop trabalhando, analisando padrões e comportamentos em tempo real.
Viu só? Não é algo distante. O Hadoop está silenciosamente aprimorando a sua experiência online. A ideia é simplificar a análise de dados para que essas aplicações funcionem para você.
Dúvidas das Leitoras
O Apache Hadoop é gratuito para usar?
Sim, o Apache Hadoop é um projeto de código aberto e totalmente gratuito para usar. Você não precisa pagar licença alguma para implementá-lo em seus projetos.
Quais as principais diferenças entre Hadoop e bancos de dados tradicionais?
Hadoop é projetado para dados não estruturados ou semiestruturados em grande escala, enquanto bancos de dados tradicionais lidam melhor com dados estruturados e transações. Hadoop foca em processamento em lote e análise, não em consultas em tempo real de pequenas quantidades de dados.
É preciso ser um programador para usar Hadoop?
Não necessariamente. Embora programadores desenvolvam e gerenciem sistemas Hadoop complexos, ferramentas e interfaces facilitam o uso por analistas de dados e outros profissionais. Você pode usar ferramentas de BI ou plataformas que abstraem a complexidade.
Hadoop é adequado para pequenas empresas?
Pequenas empresas podem se beneficiar do Hadoop se lidam com grandes volumes de dados ou dados complexos. Existem soluções mais leves e gerenciadas que tornam o Hadoop acessível para negócios de menor porte.
Como o Hadoop se compara a outras soluções de Big Data?
Hadoop é uma fundação robusta para muitas soluções de Big Data, oferecendo armazenamento e processamento distribuído. Outras soluções podem ser mais especializadas, como bancos de dados NoSQL para acesso rápido ou plataformas de cloud que integram diversas ferramentas de análise.
O Apache Hadoop é a base para lidar com grandes volumes de dados. Ele permite processar e armazenar informações massivas de forma distribuída, o que é essencial hoje em dia. Pense nele como a infraestrutura que faz tudo isso funcionar. Se você curtiu entender sobre isso, que tal dar uma olhada no que é Big Data? Compartilhe suas dúvidas e experiências!


