

O scikit-learn para machine learning é o seu passaporte para criar modelos preditivos. Você tem dados, mas não sabe como extrair insights valiosos? Pois é, essa é uma dificuldade comum. Neste post, vou te mostrar como o scikit-learn simplifica esse processo, permitindo que você construa suas próprias soluções de inteligência artificial de forma acessível e eficaz.
Desmistificando o Scikit-learn: Sua Ferramenta Essencial para Machine Learning
O Scikit-learn é uma biblioteca Python de código aberto focada em machine learning. Ele oferece ferramentas simples e eficientes para análise preditiva em dados. É como ter um kit de ferramentas completo para construir modelos de aprendizado de máquina, seja para classificação, regressão ou agrupamento. Sua popularidade vem da facilidade de uso e da vasta gama de algoritmos disponíveis.
Vamos combinar, trabalhar com machine learning pode parecer assustador. Mas o Scikit-learn simplifica muito. Com ele, você pode importar modelos pré-construídos, treinar seus dados com poucas linhas de código e avaliar os resultados de forma prática. É a porta de entrada para quem quer explorar o poder dos dados sem se perder em complexidades desnecessárias.
Confira este vídeo relacionado para mais detalhes:
Dominando o Scikit-learn: Guia Prático para Iniciantes e Entusiastas
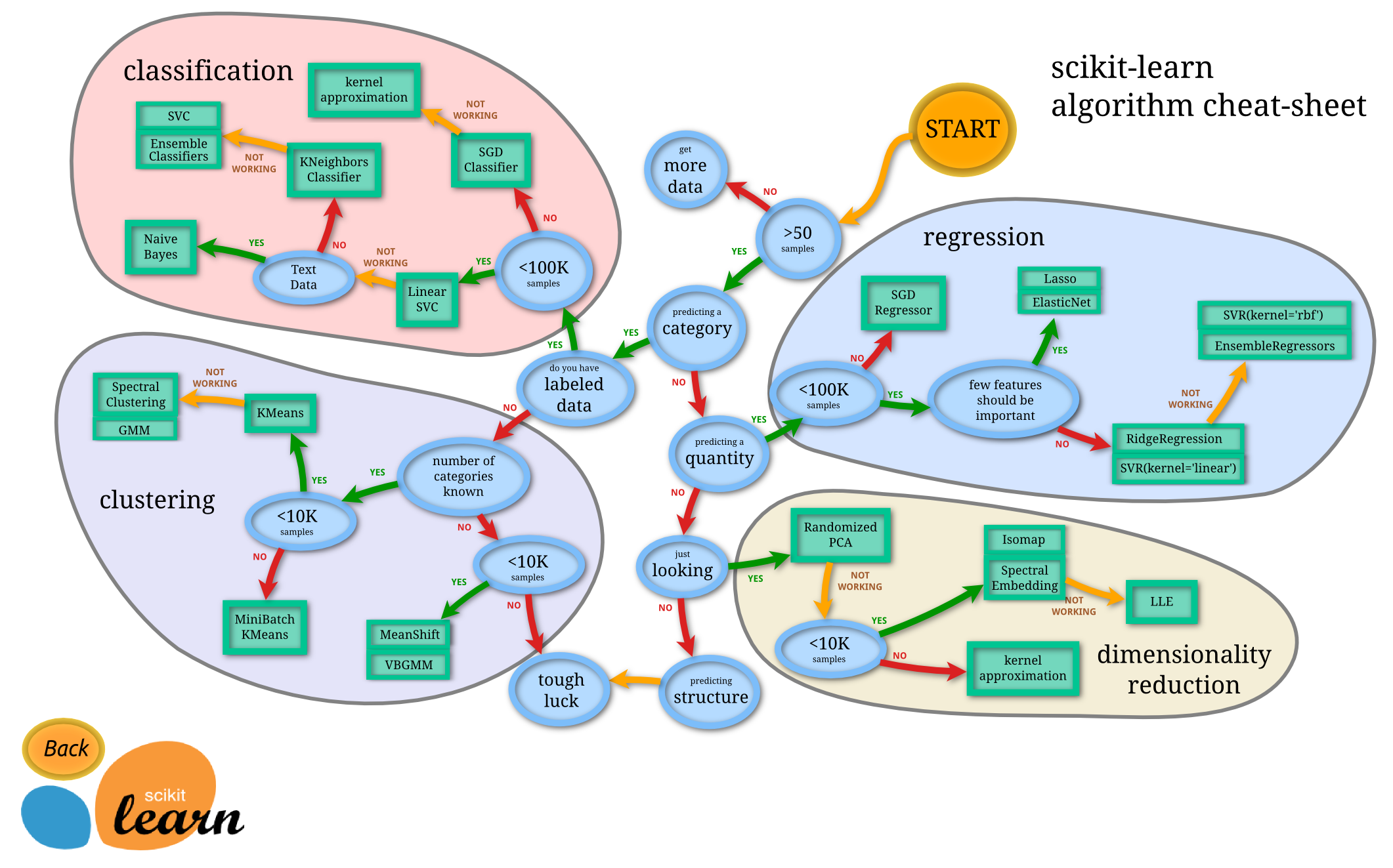
Primeiros Passos: Instalando e Importando o Scikit-learn no Seu Ambiente
Instalar o Scikit-learn é moleza. Se você já usa Python, o jeito mais rápido é pelo pip. Abra seu terminal ou prompt de comando e digite: pip install scikit-learn. Pronto! Em segundos, essa ferramenta poderosa estará disponível para você brincar.
Depois de instalar, importar no seu código Python é direto. No topo do seu script, basta colocar: import sklearn. Para usar módulos específicos, como os de modelos de classificação ou regressão, você vai importar de forma mais detalhada, tipo from sklearn.linear_model import LogisticRegression. É assim que a mágica começa a acontecer.
Com o Scikit-learn instalado e importado, você já tem acesso a uma vasta gama de algoritmos. Desde os mais simples, como regressão linear, até redes neurais e árvores de decisão. O legal é que a documentação é clara e há muitos exemplos para te guiar.
Dica Prática: Antes de sair usando, experimente importar partes menores do Scikit-learn, como from sklearn.model_selection import train_test_split. Isso te ajuda a entender como os módulos se organizam e facilita o acesso quando precisar de algo específico.

Entendendo os Dados: Pré-processamento Essencial com Scikit-learn
O Scikit-learn é uma biblioteca Python super versátil para machine learning. Ele oferece ferramentas eficientes para análise preditiva. Pensa nele como um kit de ferramentas completo para trabalhar com dados. Antes de dar qualquer instrução para o seu modelo, você precisa preparar o terreno, e o Scikit-learn faz isso de forma clara e objetiva. Ele lida com tarefas cruciais como lidar com valores ausentes ou transformar dados para que o algoritmo entenda melhor.

Um dos pontos fortes do Scikit-learn é o pré-processamento. Imagine que você tem um monte de informações confusas. O Scikit-learn tem funções para normalizar essas informações (deixar tudo em uma escala parecida), para codificar variáveis categóricas (transformar texto em números que o modelo entende) e para lidar com dados faltantes. Sem isso, seu modelo de machine learning pode dar resultados ruins ou nem funcionar direito. É como tentar cozinhar com ingredientes estragados; o resultado não vai ser bom.
Vamos combinar, ninguém quer perder tempo com dados bagunçados. O Scikit-learn simplifica bastante esse processo. Ele oferece métodos padronizados que você pode aplicar em diferentes conjuntos de dados com poucas linhas de código. Isso garante consistência e agilidade no seu projeto de machine learning. Fica tranquilo, com as ferramentas certas, essa etapa fica bem mais tranquila do que parece.
Dica Prática: Sempre que for trabalhar com dados novos, comece explorando e visualizando-os antes de aplicar qualquer pré-processamento. Isso ajuda a identificar problemas específicos que o Scikit-learn pode resolver.

Seus Primeiros Modelos: Regressão Linear e Classificação Simples
Chegou a hora de colocar a mão na massa com os modelos mais fundamentais. Pense na Regressão Linear como uma forma de prever um valor contínuo, tipo o preço de uma casa baseado no tamanho. Já a Classificação Simples é para categorizar coisas, como dizer se um e-mail é spam ou não. O scikit-learn é uma biblioteca Python fantástica que torna tudo isso bem mais acessível. Você vai ver como é direto ao ponto aplicar esses modelos.
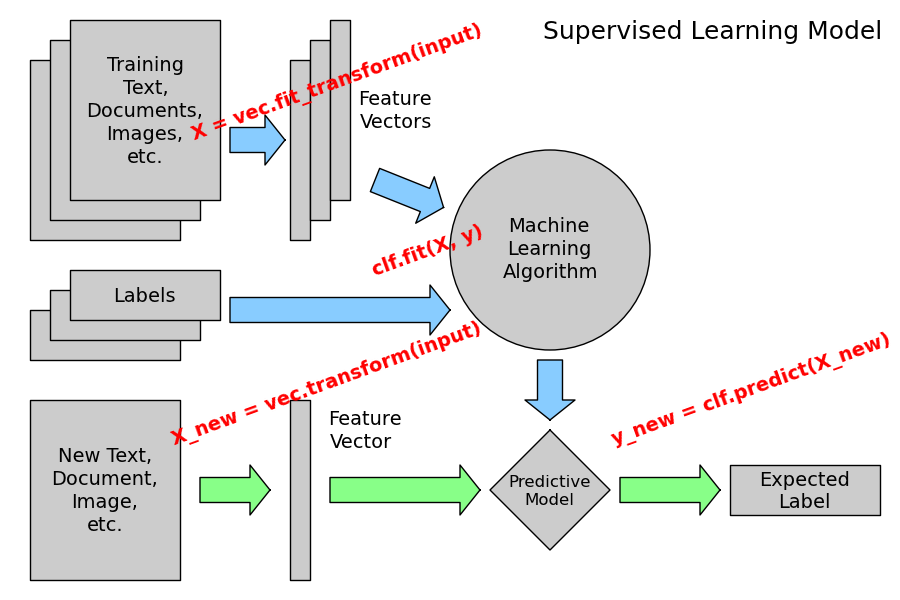
Com o scikit-learn, você vai carregar seus dados, escolher o modelo certo – seja para prever um número ou uma categoria – e treinar ele. É como ensinar um computador a reconhecer padrões. Por exemplo, para regressão, você ajusta uma linha aos seus dados. Para classificação, ele aprende a traçar limites entre as diferentes classes. O código é limpo e a comunidade em torno do scikit-learn é enorme, o que ajuda demais quando bate aquela dúvida.
A beleza desses modelos iniciais é que eles formam a base para entendermos conceitos mais avançados. Ao dominar a regressão e a classificação simples, você já ganha uma visão clara de como o machine learning funciona na prática. Experimentar com datasets pequenos para ver como os resultados mudam com diferentes parâmetros é um excelente exercício. Sempre divida seus dados em conjuntos de treino e teste. Treine o modelo com uma parte e depois valide o desempenho na outra, para ter certeza que ele generaliza bem para dados novos.
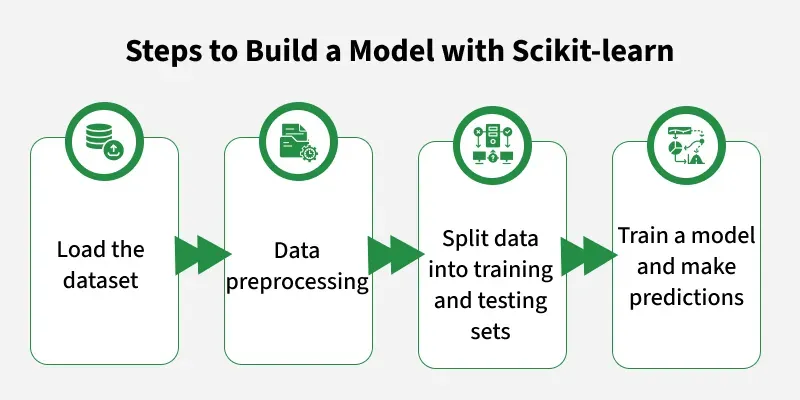
Avaliando o Desempenho: Métricas Cruciais para Entender Seus Modelos
Quando a gente trabalha com machine learning, o Scikit-learn, essa biblioteca fantástica do Python, oferece um monte de ferramentas pra gente avaliar o desempenho dos modelos. Pensa comigo: você quer que seu modelo preveja algo, certo? Seja identificar um e-mail como spam ou recomendar um filme. As métricas te dizem o quão certeiro ele está sendo nessas tarefas.
Para classificação, por exemplo, métricas como Acurácia, Precisão e Recall são essenciais. A Acurácia te diz a porcentagem total de acertos. Já a Precisão foca nos que o modelo disse que eram positivos, quantos realmente eram. O Recall, por outro lado, olha para todos os positivos reais e vê quantos o modelo conseguiu “pegar”. A escolha de qual usar depende muito do problema que você está tentando resolver. Em problemas onde um falso positivo é muito pior que um falso negativo, a precisão ganha destaque.
Para tarefas de regressão, onde o modelo prevê um valor numérico (como o preço de uma casa), a gente usa outras métricas. O Erro Quadrático Médio (MSE) e o Erro Absoluto Médio (MAE) são bem comuns. Eles medem a diferença entre o valor previsto e o valor real. Quanto menor esses valores, melhor o modelo. E não se esqueça da R² (R ao quadrado), que indica a proporção da variância na variável dependente que é explicada pelas variáveis independentes.
Dica Prática: Ao usar o Scikit-learn, explore a sub-biblioteca `sklearn.metrics`. Lá você encontra tudo que precisa para calcular essas avaliações de forma rápida e eficiente.
Seleção de Modelos: Escolhendo o Algoritmo Certo para Cada Problema
No mundo do machine learning, escolher o modelo de algoritmo correto é como escolher a ferramenta certa para um trabalho. Se você quer classificar e-mails como spam ou não, um tipo de modelo funciona. Se quer prever o preço de uma casa, outro. O scikit-learn, essa biblioteca fantástica em Python, tem uma variedade enorme de algoritmos prontos para usar. Pense neles como diferentes abordagens para resolver um problema. Alguns são bons para tarefas de classificação, outros para regressão, e ainda outros para agrupar dados sem rótulos.

A seleção do algoritmo vai depender muito do tipo de dado que você tem e do resultado que busca. Se seus dados têm categorias claras, como “cachorro” ou “gato”, você pensa em algoritmos de classificação. Se está lidando com números, como temperatura ou valor, e quer prever um número específico, aí são os de regressão. O scikit-learn organiza esses modelos de forma bem lógica, facilitando a sua vida na hora de experimentar. Cada algoritmo tem suas vantagens e desvantagens, e testar é o caminho.
No fim das contas, não existe um único “melhor” algoritmo para tudo. O segredo é entender o seu problema e testar. O scikit-learn te dá essa liberdade. Você pode rodar um modelo, ver como ele se sai, e se não estiver bom, mudar para outro em poucos minutos. É essa experimentação que leva a melhores resultados no seu projeto de machine learning.
Dica Prática: Antes de escolher um modelo complexo, tente começar com algo mais simples, como a Regressão Logística para classificação ou a Regressão Linear para regressão. Veja o desempenho delas primeiro. Muitas vezes, modelos mais simples já resolvem bem o seu problema.

Validação Cruzada: Garantindo que Seu Modelo Generalize Bem
Sabe quando a gente treina um modelo de machine learning e ele fica perfeito com os dados que a gente usou pra ensinar? Pois é, isso é bom, mas nem sempre significa que ele vai funcionar bem com dados novos, que ele nunca viu antes. É aí que entra a validação cruzada. Pensa nela como um teste final para garantir que seu modelo não decorou tudo, mas realmente aprendeu a “pensar” e a resolver problemas de forma geral. O scikit-learn tem ferramentas incríveis pra fazer isso sem complicação.

Com o scikit-learn, a validação cruzada é bem direta. Uma técnica comum é a K-Fold. Basicamente, você divide seus dados em ‘K’ partes. O modelo treina com K-1 partes e testa com a que sobrou. Esse processo se repete K vezes, usando cada parte como teste uma vez. Depois, a gente tira uma média do desempenho. Isso dá uma ideia muito mais realista de como o modelo vai se sair em situações reais, longe dos dados de treinamento. Ajuda a evitar que você se engane achando que seu modelo é mais esperto do que realmente é.
Usar validação cruzada é crucial para ter confiança no seu modelo. Ela te dá um feedback honesto. Se o desempenho variar muito entre os folds, é um sinal de alerta. Pode ser que seu modelo esteja muito complexo para a quantidade de dados, ou que os dados em si tenham problemas. O scikit-learn facilita a implementação, e não tem desculpa pra não usar. Você vai economizar tempo e dor de cabeça no futuro.
Dica Prática: Comece usando `cross_val_score` do scikit-learn para ter uma visão rápida do desempenho do seu modelo com validação cruzada. É simples e já te dá um norte.
Ajuste de Hiperparâmetros: Otimizando a Performance dos Seus Algoritmos
Pois é, no `scikit-learn`, os hiperparâmetros são aquelas configurações que você define *antes* de treinar o seu algoritmo. Eles não são aprendidos com os dados, sabe? É como ajustar as regras do jogo antes de começar a partida. Um bom ajuste faz uma diferença gritante na precisão e na velocidade do seu modelo. Sem isso, seu algoritmo pode não atingir todo o seu potencial.

Vamos combinar, ninguém quer um modelo que erra mais do que acerta. O `scikit-learn` oferece ferramentas incríveis para automatizar essa busca por bons hiperparâmetros. Métodos como `GridSearchCV` e `RandomizedSearchCV` são seus aliados aqui. Eles testam diferentes combinações de valores para você, economizando um tempão e garantindo que você explore um bom leque de possibilidades. É um processo essencial para quem leva machine learning a sério.
A chave é encontrar o equilíbrio certo. Um modelo muito complexo pode se ajustar demais aos dados de treino (o famoso overfitting) e falhar com dados novos. Já um modelo muito simples pode não capturar os padrões importantes. O ajuste de hiperparâmetros é a arte de acharmos esse ponto ideal. É um ciclo de teste, avaliação e refinamento que leva seu projeto para outro nível.
Dica Prática: Comece testando uma faixa menor de valores para os hiperparâmetros mais importantes para o seu modelo. Depois que encontrar um bom resultado inicial, expanda a busca para refinar ainda mais.
Feature Engineering: Criando e Selecionando Características Relevantes
O Feature Engineering é basicamente a arte de criar e selecionar as “características” (ou variáveis) que seu modelo de Machine Learning vai usar para aprender. É como preparar os ingredientes antes de cozinhar. Você não joga tudo na panela de qualquer jeito, né? Precisa escolher os melhores, cortar no tamanho certo, temperar. Com os dados é a mesma coisa. O scikit-learn oferece ferramentas fantásticas para te ajudar nessa etapa, desde criar novas features a partir das existentes até selecionar as mais importantes.

Às vezes, as características que você tem no seu conjunto de dados não são suficientes. Talvez você precise combinar duas informações para criar uma nova que seja mais útil. Ou talvez você tenha muitas características e algumas delas nem fazem diferença pro seu problema. Nesse caso, é bom limpá-las. O scikit-learn tem vários módulos para isso, como o `sklearn.preprocessing` para escalar e transformar seus dados, e o `sklearn.feature_selection` para te ajudar a escolher as melhores.
Não é só sobre ter dados, mas sobre ter os dados certos. Um bom Feature Engineering pode fazer seu modelo ir de “mais ou menos” para “uau!”. Pense nas particularidades do seu problema. Que informações você acha que seriam realmente importantes? Às vezes, uma ideia simples, que parece óbvia pra você, pode ser uma nova característica matadora pro seu modelo. E para quem usa o scikit-learn, existem técnicas como a codificação (encoding) de variáveis categóricas que fazem toda a diferença.
Dica Prática: Antes de sair criando 1001 novas features, experimente com algumas poucas que façam sentido para o seu problema. Teste o modelo com elas e veja se há melhora. Se sim, você pode ir expandindo.

Trabalhando com Dados Não Estruturados: Introdução ao Processamento de Texto
Muita gente acha que machine learning só funciona com números. Pois é, mas isso não é bem assim. A gente produz um monte de texto o tempo todo: emails, posts em redes sociais, artigos. Analisar tudo isso pode ser um desafio, mas é onde o processamento de texto entra em cena. Ele transforma essas palavras em algo que os algoritmos conseguem entender.

Para trabalhar com esses dados textuais, precisamos de ferramentas. O scikit-learn, por exemplo, é um kit de ferramentas fantástico para machine learning. Ele oferece várias maneiras de preparar seu texto, como a contagem de palavras (Bag-of-Words) ou a ponderação TF-IDF. Isso ajuda a dar peso às palavras mais importantes em cada documento, facilitando a análise.
O scikit-learn facilita muito a aplicação de técnicas de processamento de linguagem natural (NLP) em seus projetos. Você pode extrair características do texto, criar modelos para classificar sentimentos em comentários, ou até mesmo agrupar documentos por tema. Fica tranquilo que não é um bicho de sete cabeças com as ferramentas certas.
Dica Prática: Comece com um conjunto de dados pequeno e bem definido. Tente um exercício simples como separar emails bons de spam usando scikit-learn. Isso vai te dar uma noção clara do fluxo de trabalho.

Próximos Passos: Explorando Técnicas Avançadas no Scikit-learn
Beleza, você já pegou o jeito do Scikit-learn, que ótimo! Agora, vamos subir um degrau e falar sobre como explorar técnicas mais refinadas. Pense em coisas como otimização de modelos e técnicas de validação que vão garantir que seus resultados sejam realmente confiáveis. É aí que o Scikit-learn mostra seu poder para quem quer ir além do básico.

Quando falamos de ir além, entram em cena métodos como Grid Search ou Random Search para encontrar os melhores parâmetros para seus algoritmos. E não podemos esquecer da validação cruzada, que é essencial para ter certeza de que seu modelo não está apenas “decorando” os dados de treino, mas aprendendo de verdade. Isso é fundamental para o machine learning.
Essas abordagens avançadas te ajudam a extrair o máximo de cada algoritmo. Você vai notar uma melhora significativa na performance dos seus modelos. É um processo que exige um pouco mais de atenção, mas o retorno é certo.
Dica Prática: Para começar a explorar, tente aplicar a validação cruzada em um dos seus projetos. Você vai ver como ela revela pontos cegos que você nem imaginava.
Com certeza! Vamos montar essa tabela explicativa sobre as aplicações do Scikit-learn no nosso dia a dia. É um material bem legal pra quem tá começando ou quer dar uma revisada.
Aplicações Reais do Scikit-learn no Nosso Dia a Dia
| Item | Descrição | O Que Você Ganha | Dica do Autor |
|---|---|---|---|
| Primeiros Passos: Instalando e Importando o Scikit-learn no Seu Ambiente | O pontapé inicial. Vamos configurar tudo para que você possa usar a biblioteca sem dores de cabeça. | Um ambiente pronto para codar e testar. | Use ambientes virtuais (como `venv` ou `conda`) para evitar conflitos de dependência. É um pequeno esforço que salva muito tempo depois. |
| Entendendo os Dados: Pré-processamento Essencial com Scikit-learn | Dados raramente chegam perfeitos. Aqui, você aprende a limpar, organizar e preparar seus dados para os modelos. | Dados mais confiáveis para seus modelos. | Dedique tempo ao pré-processamento. Dados “sujos” levam a resultados ruins, não importa quão bom seja o seu algoritmo. Pense nisso como preparar os ingredientes antes de cozinhar. |
| Seus Primeiros Modelos: Regressão Linear e Classificação Simples | Vamos colocar a mão na massa com exemplos práticos. Entenda como criar modelos que preveem valores e classificam itens. | A base para construir previsões e categorizações. | Comece com problemas simples. Entender a regressão linear e a classificação com um dataset pequeno te dá uma clareza incrível antes de pular para coisas mais complexas. |
| Avaliando o Desempenho: Métricas Cruciais para Entender Seus Modelos | Um modelo bonito no papel não adianta nada se não funciona bem na prática. Aprenda a medir a “performance” real. | Saber se seu modelo realmente funciona. | Não se prenda a uma única métrica. Entenda o contexto do seu problema para escolher as métricas certas. Acurácia nem sempre é a resposta. |
| Seleção de Modelos: Escolhendo o Algoritmo Certo para Cada Problema | Existem vários tipos de algoritmos. Vamos te ajudar a escolher o mais adequado para a sua necessidade. | Mais eficiência e melhores resultados. | Conheça as características de cada algoritmo. Alguns são bons para dados lineares, outros para padrões complexos. Saber disso economiza um tempão de testes. |
| Validação Cruzada: Garantindo que Seu Modelo Generalize Bem | Evite que seu modelo “decore” os dados de treino e não funcione com dados novos. Essa técnica garante robustez. | Confiança de que seu modelo funcionará em cenários reais. | Sempre use validação cruzada. É o que te dá uma visão realista de como seu modelo vai se sair com dados que ele nunca viu antes. |
| Ajuste de Hiperparâmetros: Otimizando a Performance dos Seus Algoritmos | Modelos têm “configurações” que podem ser ajustadas. Aprenda a encontrar os melhores valores para maximizar |
Confira este vídeo relacionado para mais detalhes:
Dicas de Ouro de Quem Usa Scikit-learn na Prática
Pois é, depois de passar um tempo trabalhando com scikit-learn, fui pegando umas manhas que fazem toda a diferença. Quero compartilhar com você o que aprendi para deixar seu trabalho com machine learning mais eficiente e com resultados melhores.
Comece com o básico
Antes de pular para modelos complexos, entenda bem os algoritmos mais simples, como Regressão Linear ou Árvores de Decisão. Scikit-learn facilita isso. Treine um modelo básico, veja como ele se comporta. Isso te dá um ponto de partida para comparar depois.
Pre-processamento é chave
Nunca subestime a limpeza e a preparação dos seus dados. Use as ferramentas do scikit-learn para lidar com valores ausentes, escalar features (StandardScaler é seu amigo!) e codificar variáveis categóricas. Dados bem tratados geram modelos muito melhores.
Validação cruzada salva seu projeto
Sempre use validação cruzada (cross-validation) para avaliar seu modelo. Isso evita que você se iluda com um bom desempenho em um conjunto de treino específico e te dá uma ideia mais real de como seu modelo vai se sair com dados novos. O `KFold` ou `StratifiedKFold` são ótimos para isso.
Experimente diferentes modelos
Não se apegue a um único algoritmo. Scikit-learn oferece uma variedade enorme. Teste vários, compare as métricas de desempenho. Às vezes, um modelo que você não esperava é que vai entregar o melhor resultado.
Dúvidas das Leitoras
Preciso ser expert em programação para usar Scikit-learn?
Que nada! O Scikit-learn foi pensado para ser acessível. Com um conhecimento básico de Python, você já consegue dar os primeiros passos e criar modelos interessantes.
Quais tipos de problemas o Scikit-learn pode resolver?
Ele é um coringa! Com o Scikit-learn, você pode fazer previsões, agrupar dados semelhantes, classificar informações e até reduzir a complexidade dos seus dados. É versátil demais.
O Scikit-learn funciona apenas com Python?
Sim, o Scikit-learn é uma biblioteca Python. Para usá-lo, você vai precisar do Python instalado no seu computador. Ele se integra perfeitamente ao ecossistema Python.
Quanto tempo leva para aprender o básico do Scikit-learn?
Depende do seu ritmo, mas com dedicação, algumas semanas podem ser suficientes para entender os conceitos centrais e começar a aplicar. Foco nos exemplos práticos ajuda muito.
O scikit-learn é uma ferramenta sensacional para quem quer se aprofundar em machine learning. Com ele, você pode experimentar diferentes algoritmos e modelos com muita praticidade. Se você curtiu isso, vale a pena dar uma olhada em modelos de regressão e classificação. O que achou? Deixe seu comentário!


